
Assessment of the Confidence Calibration Test + new test
Analysis of yesterday's new test, and bug fixes

Yesterday, I posted a new cognitive test on taketest.xyz, the Confidence Calibration Test. If you want to take the test without biased results, take it now before reading further. You answer trivia/general knowledge questions like this one:
The content of the questions doesn’t matter too much, and most of these tests use trivia questions, but you can in principle use anything. There’s one based on US trivia/geography here, and another US trivia one here. There’s 2 main formats, the one using true/false and input confidence level format, and the one where you input your numerical range that it is supposed to have a certain coverage. An example of that is this test:
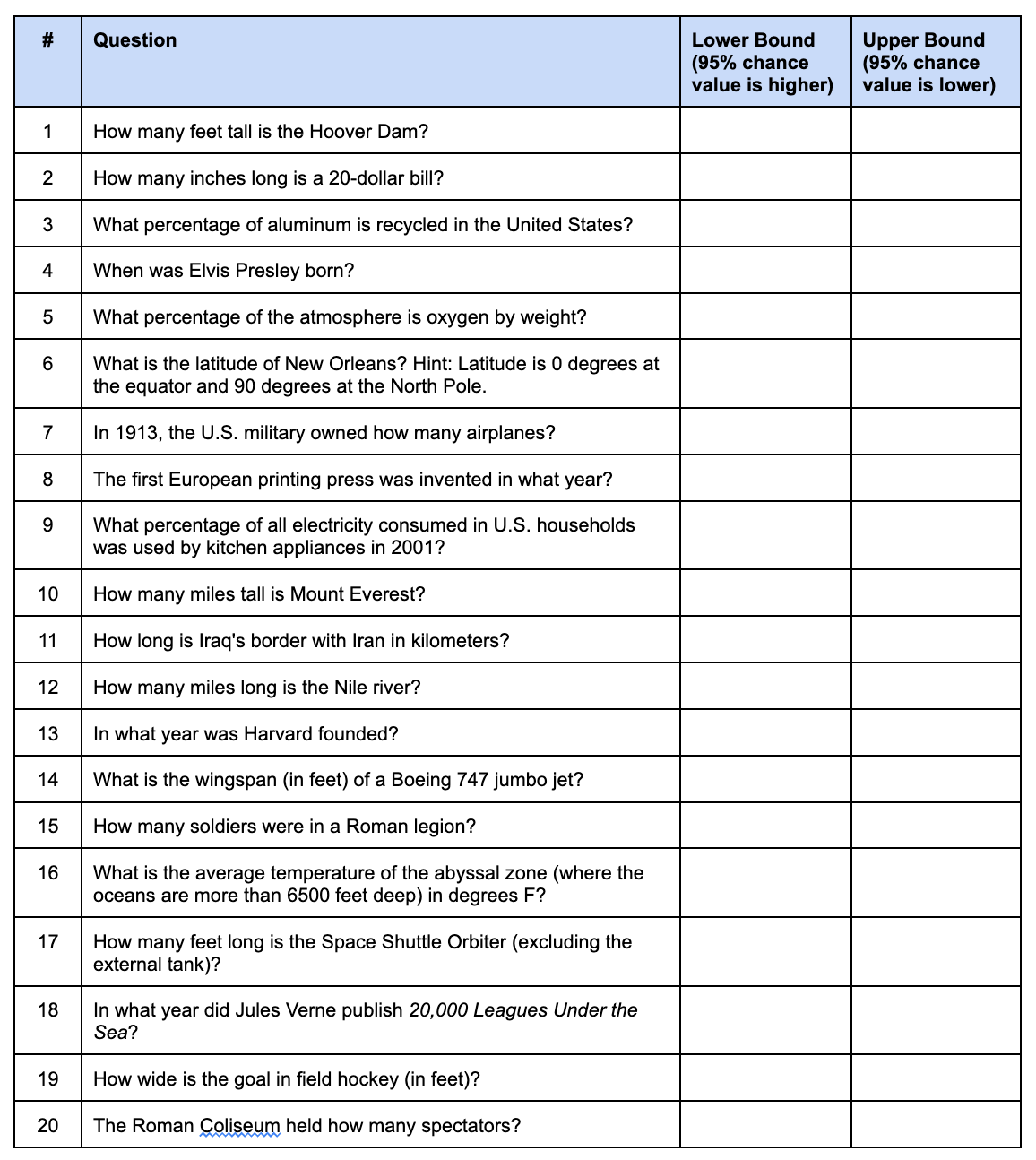
This format is harder for the users as it is not a typical format used, and it requires a lot of typing of numbers leading to data entry issues. I would think in general this therefore leads to less reliable estimates.
The test was made with Claude, by just asking it to generate a website with 120 true/false questions. I took the test myself and then told it to fix a number of questions. The ones I replaced or fixed were:
Q1: “Sahara is the largest desert” → “Sahara is the largest hot desert” (answer flipped to true)
It was a trick question based on a definition of desert that includes Antarctica.
Q6: “Dead Sea is the lowest point on Earth’s land surface” → “Lake Baikal is the deepest lake”
The Dead Sea is not a land surface.
Q13: “Mount Everest is in Nepal” → “Mount Everest is in Tibet”
Originally, it was coded as false because mount Everest peak sits at the border, and AI doesn’t think this means it is “in Nepal”. Honestly, it is still a bad question.
Q41: “Bananas are berries” → “China produces more rice than India”
Trick question based on unusual fruit/berry definitions used in botany that are opposite of ordinary language. The new question turns out to be very bad too because China and India actually produce the same amount of rice, within 1%.
Q68: “Dracula was written by an Irish author” → “War and Peace was written by Dostoevsky”
He was half English by descent, and some might interpret Irish as referring to the ethnic group.
Q93: “Java was developed at Sun Microsystems” → “Python is named after Monty Python”
Too obscure.
Q98: “Internet and WWW are the same thing” → “Russia spans 11 time zones”
Original concerns obscure technical difference. In normal language use, they mean the same thing.
Q100: “Linux created by a Finnish computer scientist” → “The human stomach produces a new lining every few days.”
Linus is a Swedish Finn, so same issue with nationality vs. ethnicity as above.
Q104: “White chocolate contains no cocoa solids” → “Iceland has no standing army”
Question was about the exact form of cocoa, butter vs. solid.
Q106: “Coffee is made from a bean” → “Coffee beans grow on trees”
Another botany akshualy vs. everyday speech. The second version is also a botany trick question.
Q109: “A banana is an herb” → “The Moon is slowly moving away from Earth”
Another botany trick question.
Q110: “The dot over i and j is called a tittle” → “More people in Bangladesh than Russia”
Too obscure.
Q114: “Polar bear fur is transparent” → “An octopus has blue blood”
Autistic distinction between ‘transparent’ and ‘white’.
As you can see, I didn’t do a great job of fixing all the questions and more remain quite suboptimal as we will see. Nevertheless, users should take this ‘potentially bad question’ uncertainty into account, and if such questions are a small % of all questions, the test will work fine.
Regarding the data, the test now has complete data from 559 people taking the test for the first time (some people take the tests multiple times), so let’s have a look at it. We have data on 2 levels: 1) we have subjects, and their various scores, and 2) we have items and their statistics. Let’s start with the person level. When you take the test, you will get a few scores:
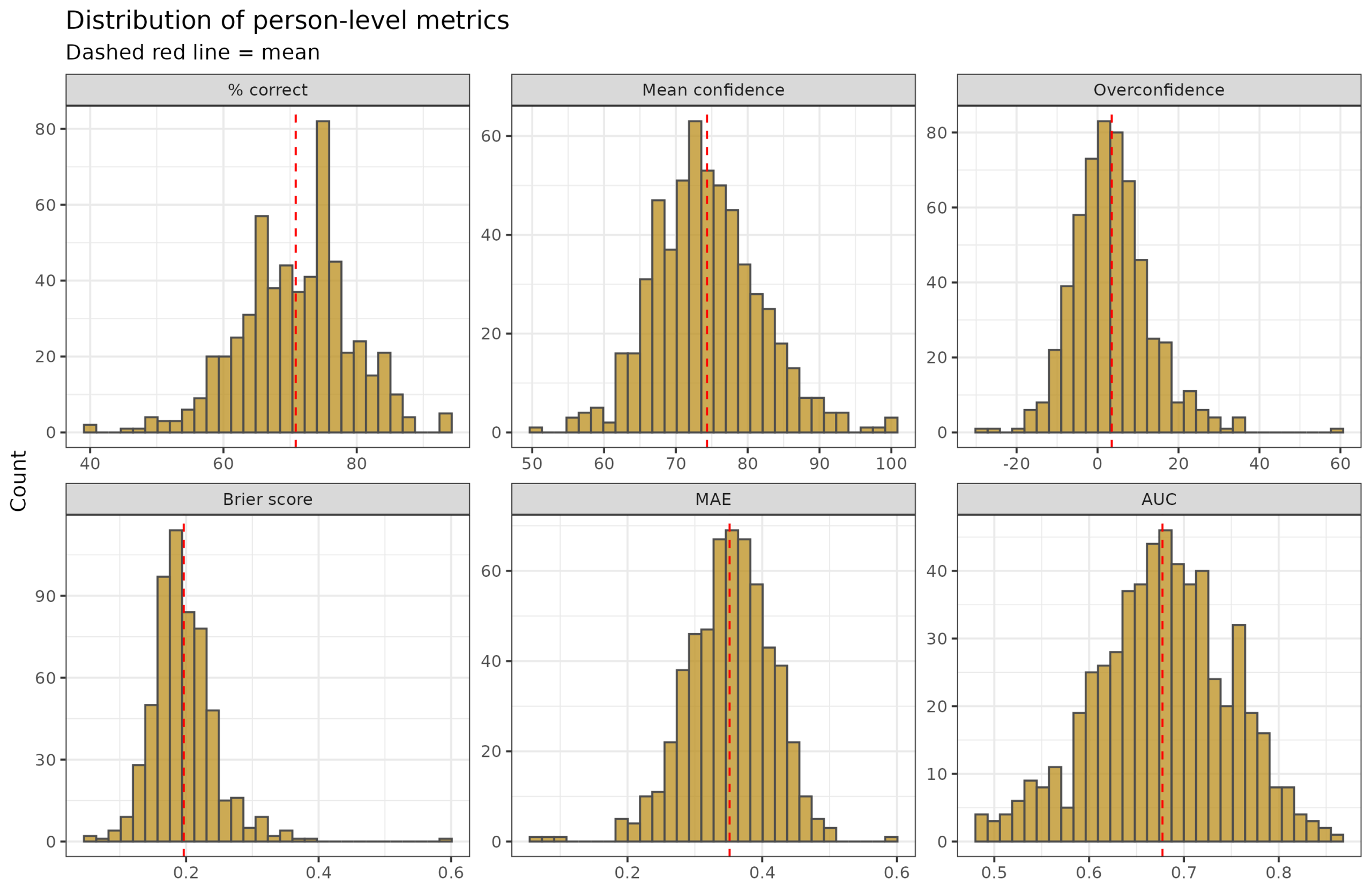
% correct is the % of questions you got correct, the site will also show the absolute count. There are 120 questions, so these are close to the same value.
Mean confidence is the average confidence given for the chosen answer. For perfectly calibrated people, this value is the same as their % correct.
Overconfidence is the difference between the two above, that is, if your confidence levels implied you got 100 correct but you only got 90, the score is 100-90 = 10. You were overconfident by 10 questions in aggregate.
MAE = mean absolute error is the distance between the confidences given and the truth, so if you give 90% to A being true and it is true, the deviation is 0.1. If you thought it was false with 90%, the deviation is 0.9. The Brier score is conceptually the same but nonlinear and has some nice mathematical features at the cost of being less intuitive.
AUC = Area Under Curve, commonly used accuracy metric in machine learning. 0.5 is random and 1.0 is perfect. The name comes from plotting values on a plot and finding the area under the line. It also has a connection to Cohen’s d, as in it is based on the distance between the probability distributions you gave for true and false statements. Thus, if you gave 100% confidence in all true statements, and 0% confidence in all false statements (100% in them being false), then the Cohen’s d between these distributions is infinite and the value becomes 1. You don’t need to care about the mathematics of it except to know that 0.5 is chance and 1.0 is perfect. The main advantage of AUC is that it is relatively independent of the ratio of cases to controls, which affects many other metrics of binary classification.
These are the correlations for the subjects between these metrics:
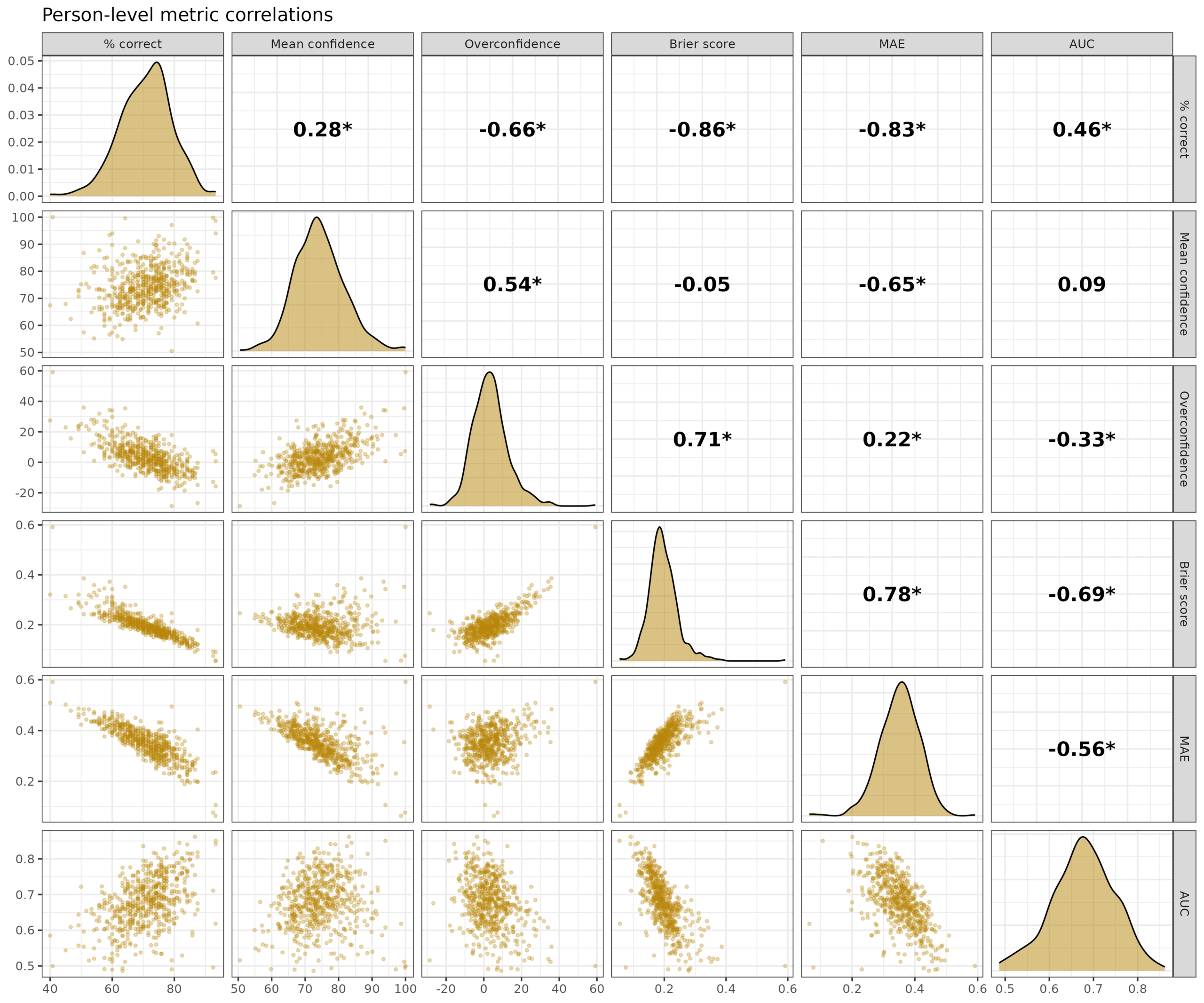
Most of them have at least decent correlations with each other but have different meanings. For instance, you could answer every question correctly with 50% confidence, and you will get 100% correct, but a bad score on the others. For interpretation, overconfidence is tricky because 0 is the best value, so in theory it should have nonlinear U shaped relationships to others, but it doesn’t. It is also mathematically impossible to be overconfident if you get everything correct, which necessitates a negative overconfidence score unless you answered 100% confidence to every question.
Regarding the questions, we can treat this as just another general knowledge test and analyze it using a simplified 1 factor model with IRT. If we do this, we get this:
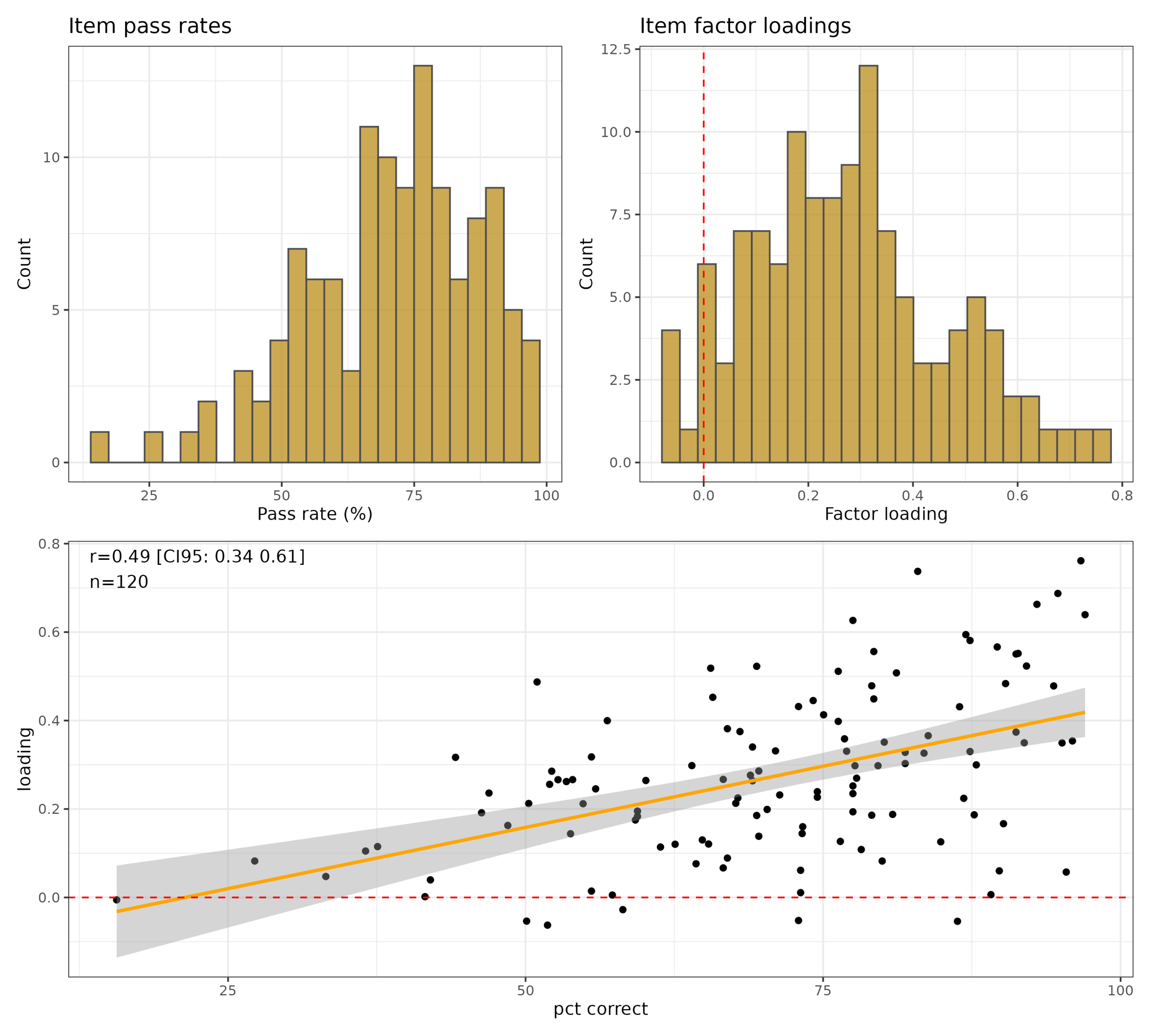
Since these are true or false questions, the guessing rate is just 50%, and any question with below 50% suggests users misinterpret the question, it is scored incorrectly, or there is some trick to it. Usually, when you make a scale/test, such questions are dropped. Similarly, the loadings distribution show that 9 questions have negative factor loadings and most have loadings below 0.30, a typically used cutoff for bad items. The items are not working very well in general as a measure of general knowledge. Still, because it has 120 items, it still achieves a reliability of 0.85, which is decent. Item pass rates and loadings are theoretically unrelated, but empirically may be related. We see a decent positive correlation, with a subset of items having below 50% pass rates and low loadings. These are the items with less than 40% pass rate:
Q76. Edvard Munch’s The Scream depicts a person screaming (15.6%, False)
This is a bad question since this is indeterminate.
Q34. Magellan completed the first circumnavigation of the globe (27.2%, False)
It’s somewhat of a trick because he died on the journey and thus didn’t complete it.
Q117. A bolt of lightning contains enough energy to power a house for a month (33.2%, False)
There’s a lot of popular articles about this, but getting a determinate answer is hard since obviously measurement is difficult. The best I could find is that for cloud-to-ground strikes, they contain about 0.8 GJ, which is 222 kWh, which covers electricity use for a US house for 7 days, EU one for 11-15 days, and 3rd world for much longer. It could be taken as true if one interprets as only electricity and uses a world median house, it could power for about a month. It’s not a great question.
Q77. The first feature-length animated film was made by Disney (36.6%, False)
Most people think of Snow White, the first US one, but there were others before, most of which are now lost. Not a trick just hard.
Q84. The human nose can detect over one trillion scents (37.6%, True)
Based on a contested study that got popular. Bad question.
These are the questions with very bad loadings, < 0.10:
Q59. Vincent van Gogh sold only one painting during his lifetime (loading: -0.06, 51.8%)
Q65. Charlie Chaplin once lost a Charlie Chaplin lookalike contest (-0.05, 86.3%)
Q13. Mount Everest is in Tibet (-0.05, 50.1%)
Q41. China produces more rice than India (-0.05, 72.9%)
Q45. Glass is a liquid that flows very slowly (-0.03, 58.2%)
Akshually definition question between liquid and “amorphous solid”.
Q76. Edvard Munch’s The Scream depicts a person screaming (-0.01, 15.6%)
Q87. Most of the dust in your house is dead skin (0.00, 41.5%)
Q106. Coffee beans grow on trees (0.01, 57.3%)
Q108. Coca-Cola originally contained cocaine (0.01, 89.1%)
Q60. Beethoven was completely deaf when he composed his 9th Symphony (0.01, 73.1%)
Q8. Tokyo is further north than New York City (0.01, 55.5%)
Q61. The Mona Lisa has no eyebrows (0.04, 42.0%)
Q117. A bolt of lightning contains enough energy to power a house for a month (0.05, 33.2%)
Q70. Michelangelo painted the ceiling of the Sistine Chapel (0.06, 95.4%)
Q33. The Titanic sank on its maiden voyage (0.06, 89.8%)
Q69. Tchaikovsky composed The Four Seasons (0.06, 73.1%)
Vivaldi.
Q74. Moby-Dick was a commercial success when first published (0.07, 66.6%)
Q83. Babies are born with about 270 bones (0.08, 64.3%)
Q17. Sweden and Norway share the longest land border in Europe (0.08, 80.0%)
Claude originally rated this as false for some reason. It narrowly beats the Russia-Ukraine border, but it is true.
Q34. Magellan completed the first circumnavigation of the globe (0.08, 27.2%)
Q39. Oxygen was discovered before hydrogen (0.09, 67.0%)
Comes down to what “discovered” means, whether being isolated counts or also had to be recognized as an element in some proto-chemistry sense.
Many of these we have seen before, most of the others seem OK, but perform poorly for some reason.
In terms of the overall level of calibration seen, we can group responses by confidence level and the actual correct %:
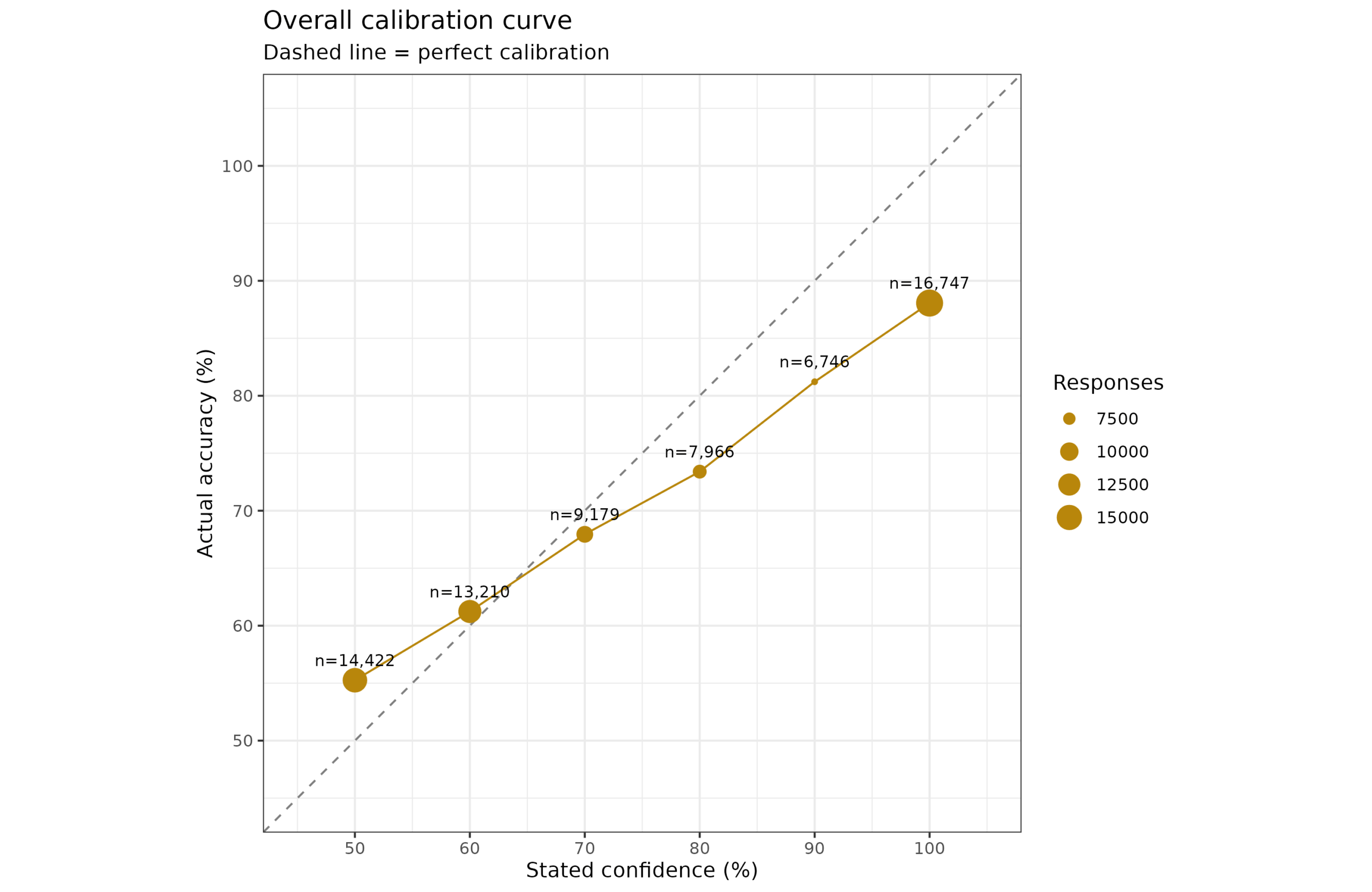
This is the aggregated item version of the usual Dunning-Kruger pattern. On average, when subjects said they were 100% confident, they were right about 87% of the time. On the other end, when they said 50%, they were right 55% of the time. By the size of the points you can also see that people rarely used the intermediate probabilities, using far too many 50%’s and 100%’s. Here’s the person-level version:
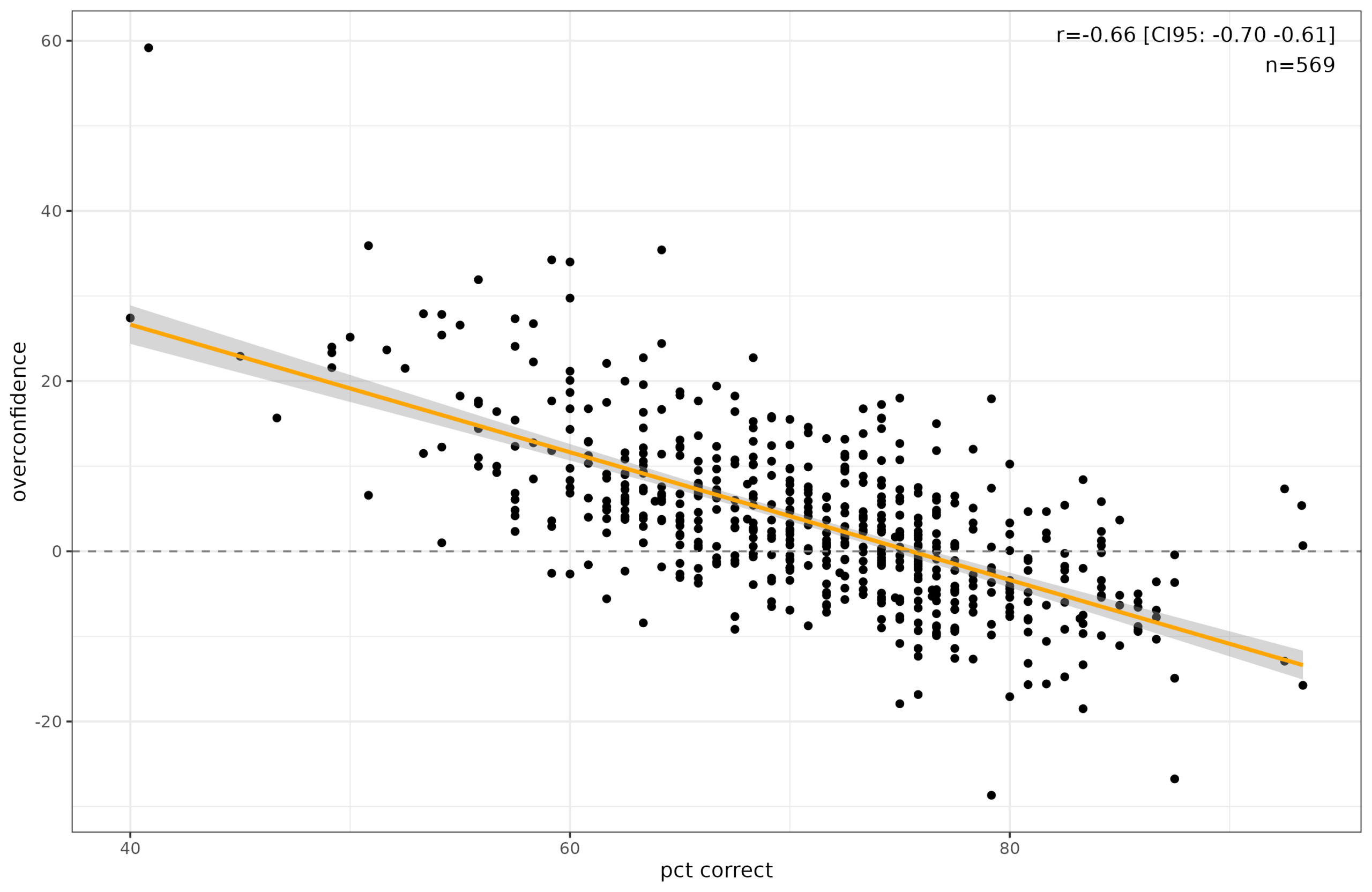
The people getting 75+ questions right were somewhat underconfident, and everybody else was overconfident. It is a common finding that people are in general bit overconfident. Here’s the distribution of overconfidence as seen in a study from the UK “nudge” unit:
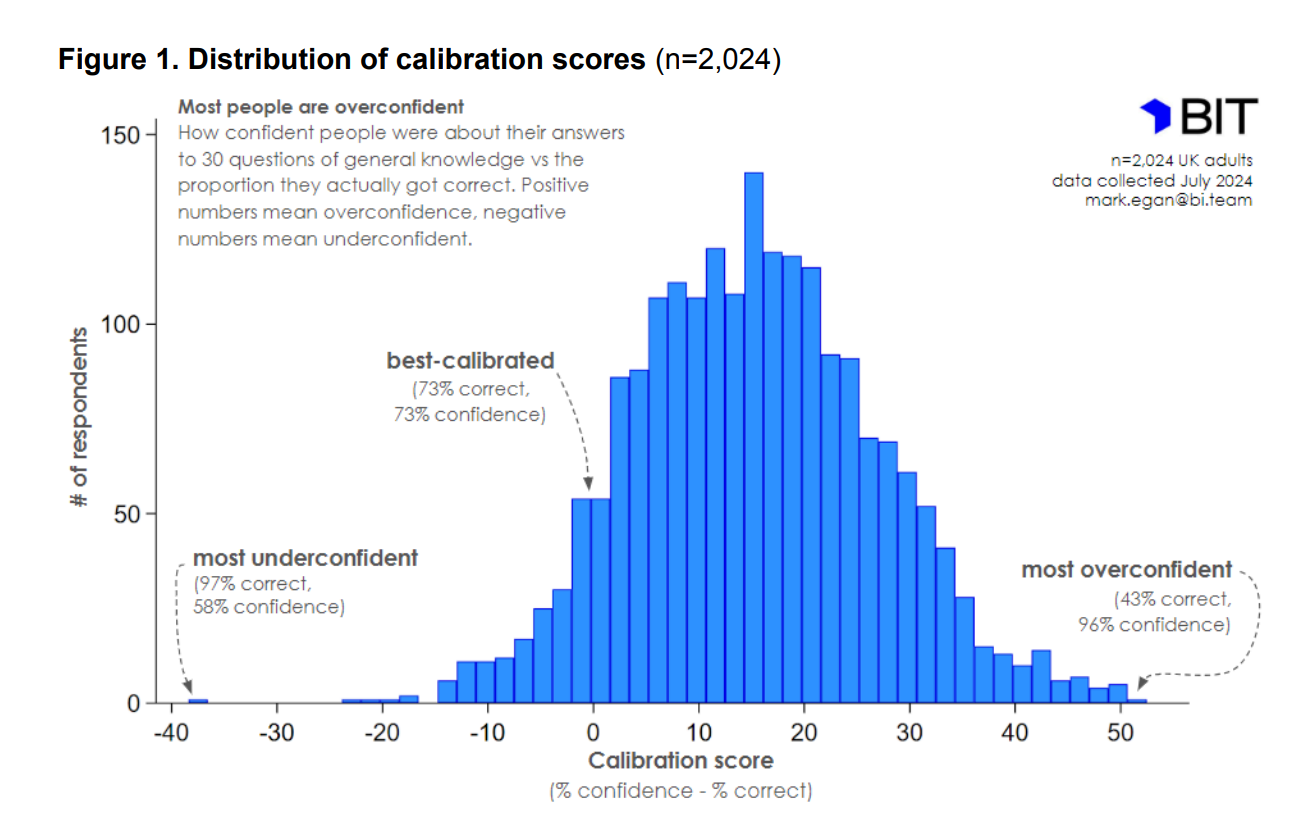
Why do we care about overconfidence? Well, it has some practical consequences. A study of eye witnesses found that they too were overconfident, more so than for general knowledge questions:
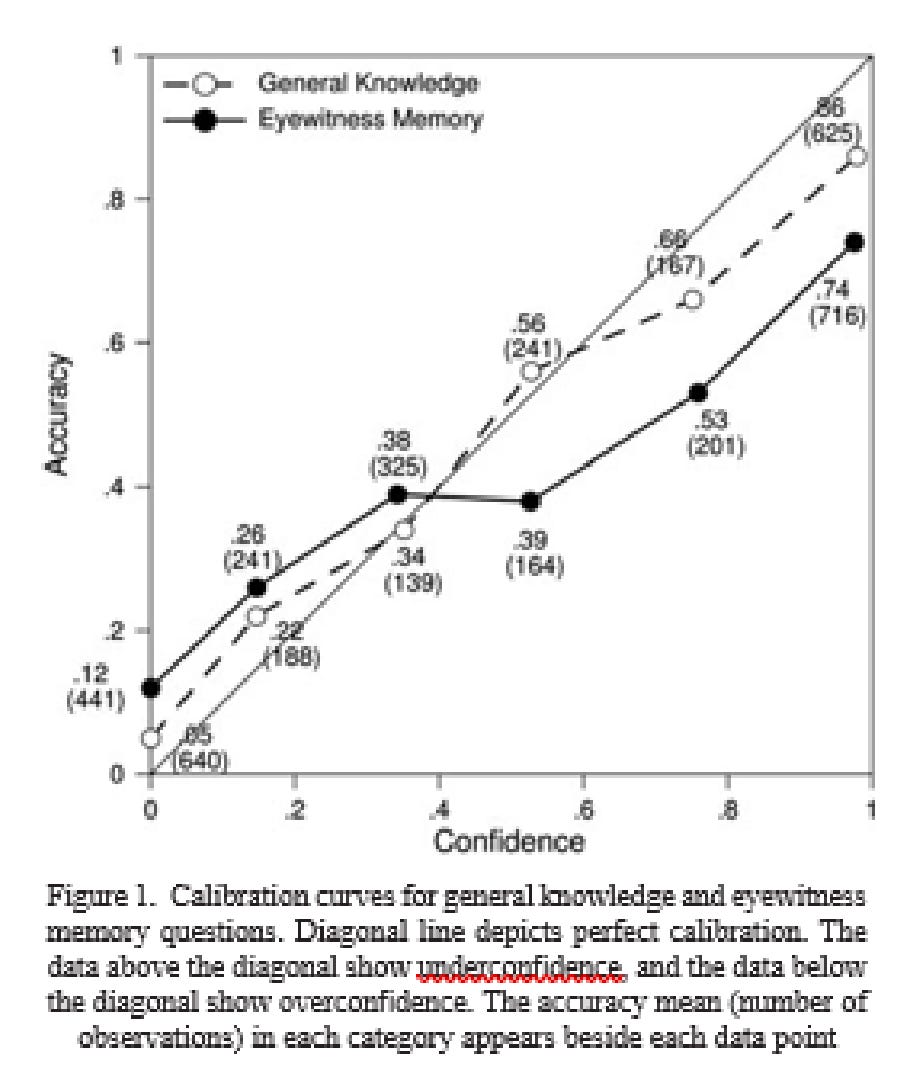
Sorry, the source quality is low.
OK, so how do these scores that people are given correlate with other cognitive test results? The new correlations page on taketest allow you to see these:
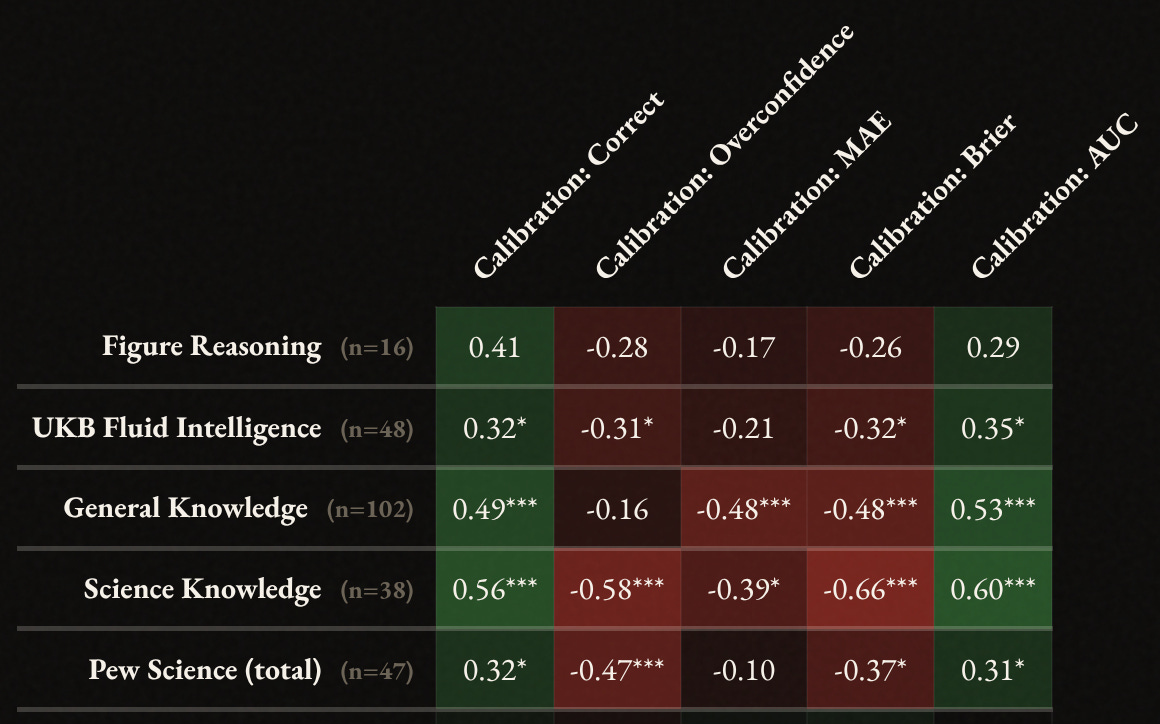
The sample sizes for people having taken the calibration test and some of the cognitive tests are not great, but they are OK for getting a general impression. It looks like it doesn’t matter too much which calibration test metric is used insofar as correlations with intelligence tests are concerned, except perhaps that overconfidence and MAE are worse. This is interesting, but the central claim of the LessWrong/rationalist idea of debiasing is that rationality has independent positive causal effects from general intelligence (g) itself. We unfortunately cannot test this here and there is little research on this question to my knowledge. The fact that we observe about the same correlations between the simple sum scoring of the answers and the other metrics with other cognitive tests does not bode well for the prospect of having incremental validity.
Overall, I would say the test works despite some bad items. I could replace the bad questions with others but this would make comparison with the earlier results difficult. The best I can do is shorten the test by removing the bad items from consideration, and I might do that, in which case it may become a 70-item test (dropping 50 worst items). This kind of pruning step is in fact common for the creation of scales, though usually it is done in several stages which we can’t easily do here. The main lesson is that I should have given AI more clear instructions: 1) avoid trick questions involving technical vs. ordinary language definitions, 2) only use facts that have definitive answers that are not a close call or which might change soon.
Regarding the alternative format, the numerical range input, I’ve created a new test for trying out this version. Once enough people have taken this variant, we can compare the person-level metrics to see how well the formats agree. Note that many versions use 95%, 90% or even 50% intervals. The latter is statistically optimal since it allows one to clearly detect under- and overconfident people, which is not possible with 95%. 50% intervals are psychologically unusual though. As a reasonable compromise between statistical utility and psychological sensibility, I’ve chosen 75% confidence intervals. Thus, input ranges that you think give you 3 out of 4 chances of containing the true value.
By the way, here are my scores on the old test:

I said "True, 50%" for all items where I had no idea and got 70% of those correct and therefore scored "-10.3 underconfident" on the whole, which suggests a bias in the test toward questions with true answers. A correct estimation would likely have scored me slightly overconfident.
Our attention spans are shot, I feel 120 trivia questions are too many. And having 3 questions about the number of bones in the body is definitely too many.