
Hiding sex differences: not a myth


Russell Warne has a new post: Implications of average group differences for the design of intelligence tests
He writes:
The implication is that if test creators can force an average difference to disappear for one pair of groups (i.e., males and females), then any differences or lack of differences are also engineered into the tests. If this were correct, it would undermine Murray’s discussion of average IQ differences between races because those differences would be nothing more than an artifact of test creation.
There is no evidence whatsoever to indicate that test creators are purposefully creating or eliminating differences in average IQ scores for any demographic groups. I have never found any such procedure mentioned or used in the test manuals or technical documentation for any intelligence, cognitive, or academic test.
The closest thing I can find to support this assertion is that many test battery creators like to balance the number of verbal and non-verbal tasks on a test, a practice that dates back to David Wechsler’s original test for adults (the Wechsler-Bellevue) in 1939. Because, generally, females tend to excel on verbal tasks and males tend to excel on non-verbal tasks, some people take this to indicate that Wechsler was trying to equalize average IQs for the two sexes. However, this is not true for two reasons. First, Wechsler balanced verbal and non-verbal tasks because his experience led him to believe that the highly verbal Stanford-Binet intelligence test was not measuring the full breadth of intelligence because it had so few non-verbal tasks (Boake, 2002).
Ignoring the argument here and focusing on the historical claim. Did test creators try to reduce sex differences through test and item selection? Warne says no evidence. Here's Richard Lynn in 2017 in his meta-analysis and review article: Lynn, R. (2017). Sex differences in intelligence: The developmental theory. Mankind Quarterly, 58(1), 9.
It should be noted that this male advantage is consistently present despite efforts by test developers to construct tests on which males and females obtain the same IQs. Thus “From the very beginning test developers of the best known intelligence scales (Binet, Terman, and Wechsler) took great care to counterbalance or eliminate from their final scale any items or subtests which empirically were found to result in a higher score for one sex over the other” (Matarazzo, 1972, p. 352); and “test developers have consistently tried to avoid gender bias during the test development phase” (Kaufman & Lichtenberger, 2002, p. 98). The Wechsler tests have reduced the true male advantage by excluding measures of spatial perception and mental rotation on which males obtain higher scores than females by 9.6 and 10.9 IQ points, respectively (Voyer, Voyer & Bryden, 1995); and also by excluding tests of mechanical abilities on which 18 year old males have an advantage of .72d (10.2 IQ points) (Hedges & Newell, 1995). This has been noted by Eysenck (1995, p. 128), who adopted my estimate of a 4 IQ point male advantage: “Allowing for the fact that Wechsler made every effort to equalize IQ between the sexes... we may perhaps say that an IQ difference of four points would be a conservative estimate of the true difference.”
Matarazzo, 1972 is an old rare book (Matarazzo, J.D. (1972). Wechsler’s Measurement and Appraisal of Intelligence. Baltimore: Williams & Wilkins.), I can't find an ebook of it, but I ordered a physical copy for 5 euro off Amazon. However, I can find a copy of Kaufman & Lichtenberger (Kaufman, A. S., & Lichtenberger, E. O. (many editions) Assessing adolescent and adult intelligence. John Wiley & Sons.). They write:
The overall trend on the WAIS-III and other tests is for males to score slightly higher than females on global IQ scales, though there are notable exceptions (e.g., processing speed), but these gender differences are of no practical con-sequence. With large sample sizes, like those found in the standardization samples, even differences of 2 points are likely to be statistically significant when each variable is treated separately. However, such small differences are not of practical significance. Furthermore, the results of gender differences on major intelligence tests are of limited generalizability regarding a theoretical understanding of male versus female intellectual functions. The results are contaminated because test developers have consistently tried to avoid gender bias during the test development phase, both in the selection of subtests for the batteries and in the choice of items for each subtest. Matarazzo (1972) pointed out: “From the very beginning developers of the best known individual intelligence scales (Binet, Terman, and Wechsler) took great care to counter-balance or eliminate from their final scale any items or subtests which empirically were found to result in a higher score for one sex over the other” (p. 352; Matarazzo’s italics). According to Wechsler (1958): “The principal reason for adopting such a procedure is that it avoids the necessity of separate norms for men and women” (p. 144).
So Kaufman and Lichtenberger agree with Lynn's assessment about males scoring higher in general, and they even quote Wechsler himself. So let's check out what Wechsler has to say in detail (Wechsler, D. (1958). The measurement and appraisal of adult intelligence.):
In tying to arrive at an answer as to whether there are sex differences in intelligence much depends upon how one defines intelligence, and on the practical side, on the type of tests one uses in measuring it. The contemporary approach, contrary to the historical point of view, adopts a sort of null hypothesis. Unfortunately this procedure turns out to be a circular affair since the nature of the tests selected can prejudice or determine in advance what the findings will be. In constructing an intelligence scale it is possible by initial selection to combine one's test in each a any as to minimise or cancel out sex differences. This has been the usual procedure of most test constructors. The principal reason for adopting such a procedure is that it avoids the necessity of separate norms for men and women.
As regards the W-B I, the original standardisation data showed small but positive sex differences on Full Scale scores in favor of female subjects. Subsequent studies (73, 263) again revealed see differences, but this time in favor of men. In attempting to account for the discrepancy the author at first was inclined to interpret the observed findings as due primarily to sampling differences, but the consistent findings of the later studies showed that men may be expected to do better than women on the W-13 I as a whole, and on the Performance part of the Scale in particular. The differences are not large but for the most part significant.
The some trend is now revealed in the WAIS data. Here again, the differences are small, at least small enough to make unnecessary separate WC norms, but sufficient to warrant further analysis of tart findings. The WAIS mean and standard deviations for Verbal, Performance and Full Scale by age and sex are given in Table 37.
So not only does Wechsler agree that this procedure was used, he says it was the usual procedure for most test constructors! This is David Wechsler, the constructor of the most used and highest regarded intelligence test, and he says this procedure was the "usual procedure". And he also agrees men keep outscoring women on the composite scores despite this.
I am pretty sure I saw some references to older works commenting on this aside from Matarazzo (that we are waiting on), but for now, I think we have sufficient material here to conclude the opposite of Warne. Anyway, I went further. Google Scholar was surprisingly useless in providing me with papers that cite Matarazzo. However, I found that searching for his famous quote on test construction on regular Google was a lot more useful. It led me to Jensen 1980 p. 624 (Bias in Mental Testing) who wrote:
General Intelligence. The most widely used standardized tests of general intelligence have explicitly tried to minimize sex differences in total score by discarding those items that show the largest sex differences in the normative sample and by counterbalancing the number of remaining items that favor either sex. This is true, for example, of the Stanford-Binet and the Wechsler scales of intelligence. Such tests, therefore, obviously cannot be used to answer the question of whether there is in fact a true difference between males and females in general intelligence. The particular mix of various items in any omnibus type of test could make the sex difference go in either direction. The fact that the differences actually found in most studies hover close to zero only indicates that the test constructors have been reasonably successful in their attempts to balance out any overall sex difference by careful item selection. The practice of eliminating and counterbalancing items to minimize sex differences is based on the assumption that the sexes do not really differ in general intelligence.
McNemar (1942, Ch. 5) justifies this procedure, in the case of the Stanford-Binet, with the argument that test batteries of extensive scope and varied content, unselected with respect to sex, generally show very small and inconsistent sex differences in total scores from one sample to another. Also, the particular items that show large sex differences in percentage passing can usually be accounted for in terms of experiences or training that are typically associated more with one sex than with the other. McNemar makes another important observation regarding the extremely varied pool of Binet test items: no one type of item consistently favors either sex. The sex differences in item difficulty are apparently more a function of specific item content than of the types of basic abilities called for by the item. Yet with the very large standardization samples, even quite small sex differences in percentage passing an item show up as highly significant statistically. The 190-item Stanford-Binet test contains 12 items on which girls significantly (p < .01) surpass boys and 16 items on which boys significantly surpass girls. These items are sufficiently well balanced that the total IQ difference between the sexes in any large sample is practically negligible. The same is true of the Wechsler tests.
OK, so Jensen repeats the same claim, but importantly, gives another primary source citation: McNemar, Q. The Revision of the Stanford-Binet Scale. Boston: Houghton-Mifflin, 1942. It turns out this book is also free to read! So here, we get the smoking gun. McNemar writes:
It is not our purpose to discuss at length the importance of sex differences, nor shall we attempt an explanation of, or rationalisation for, the interest of psychologists in the problem. One might, by some speculation, arrive at the notion that the reason for a section on this topic in so many research reports can be subsumed under one of the following three headings: a real interest in sex differences per se, or an interest incidental to the problem of uncontrolled variables in experimental work, or a mere following of the tradition of including a section devoted to sex differences. All three types of motivation have contributed to our knowledge concerning differences due to sex. Whether or not such differences as have been demonstrated have social significance may be open to question, but as regards their import for experimental control there can be no question; for when sex differences are not present, conclusions from an experiment become more general and lees subject to qualifications.
One who would construct a test of intellectual capacity has two possible methods of handling the problem of sex differences. (1) He may assume that all the sex differences yielded by his test items are about equally indicative of sex differences in native ability. In this case separate norms for the sexes will be Necessary if the means for total score on the battery show appreciable discrepancy for the sexes. Ill He may proceed on the hypothesis that large sex differences on items of the Binet type are likely to be factitious in the sense that they reflect sex differences in experience or training. To the extent that this assumption is valid he will be justified in eliminating from his battery the test items which yield large sex differences, and by this method may be able to dispense with separate norms.
There are, of course, limits beyond which one would hesitate to go in defense of either of these methods. For example, the person inclined to favor separate, norms for the sexes would nevertheless avoid using test items obviously unfair to one sex or to the other, such as making a dress or constructing a kite. On the other hand, one who favors the second procedure must admit that it rests upon an assumption, and that in the case of certain test items the assumption may be in error. Certainly the absence of sea differences cannot be proved by the simple expedient of refusing to use items which show such differences! The authors of the New Revision have chosen the second of these alternatives and have sought to avoid using test items showing large sex differences in per cents passing. Their choice rests upon the empirical fact that test batteries of extensive scope and varied con-tent as a rule yield only small sea differences in total scores, and that when individual test items do show large sex differences these can often be accounted for in terms of known differences in environment or training. However, because of the limited number of test items available at a given age level it was not possible to eliminate all of the items which showed sex differences. The ex-tent to which sex-differentiating items were balanced will become evident in the ensuing section of this chapter. Subsequently, information will be given on those retained and eliminated items which yielded statistically significant sex differences.
Thus, he says this revision of the Stanford Binet (i.e., SB2, 1937: Second Edition by Terman and Merrill) was directly constructed to remove items showing sex differences in intelligence. In fact, there is a summary of the items removed:

(They removed items with p < .01 based on a chi square test.)
The reader can count here: there are 13 items that favored girls and were removed and 25 that favored boys that were removed. If you look at the ages, too, you can see that the male favoring items were in the later teens, and the female favoring items were in the earlier ages. Thus, in fact, the procedure here has directly suppressed evidence for Richard Lynn's developmental theory! In a truly bizarre turn of history, we later have people claimed there are no sex differences. In point of fact, this procedure is not itself sufficient to completely remove gaps. The resulting scores are given too:
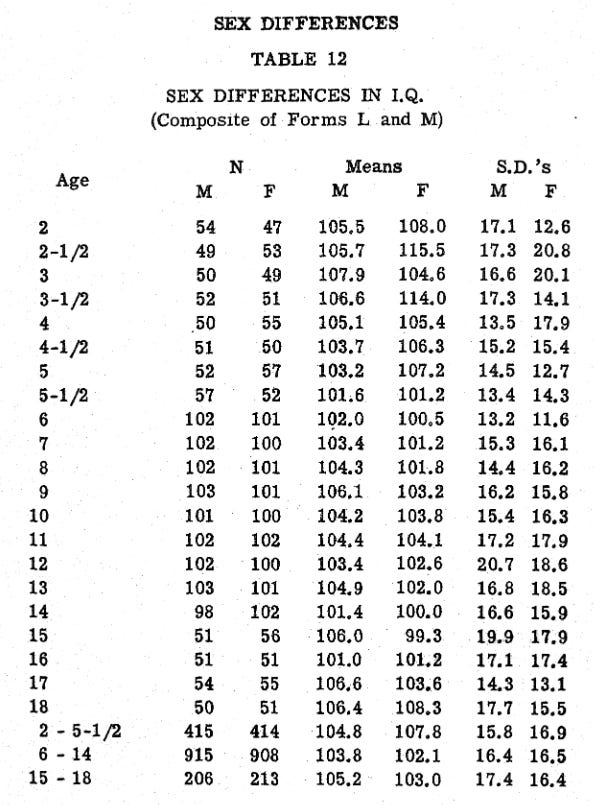
Here we see that there is a female favoring at earlier ages, and male favoring at later ages. This table is based on "the final scoring procedure", i.e., after the offending items were removed.
I reached out to Alan Kaufman, the one author of the Kaufman and Lichtenberger above. He had this to say, posting with his permission:
Emil,
Thank you for sharing your blog post. There are a few pertinent points that I think should be considered: 1. When I worked with Wechsler in the early 1970s to develop the 1974 WISC-R, we evaluated gender bias by using item bias statistics. That approach looks at the rank ordering of the items on a subtest to determine whether an item is biased against boys or girls. IT NEVER LOOKS AT WHETHER ONE GROUP OUTPERFORMED THE OTHER; ONLY WHETHER AN ITEM MIGHT BE MUCH EASIER FOR ONE GROUP THAN THE OTHER WITHIN A SUBTEST. When that occurs, it is presumed that the item is biased against the group that finds that item relatively more difficult. This items are eliminated or counterbalanced. For example, on WISC-R Picture Completion, the screw missing the “slit” for the screwdriver was found to be biased against girls. The girl missing a sock was biased against boys. Both items were retained as they counterbalanced each other; eliminating both items would have damaged reliability of the subtest. 2. That same procedure was used to eliminate or counterbalance items biased against an ethnic group. In that case items biased against Black individuals or against Hispanic individuals were almost always eliminated, only occasionally counterbalanced. 3. Item bias procedures of this sort have been used in the development of all subsequent Wechsler Scales and every Kaufman scale. In no instance was a new Wechsler subtest (post David Wechsler) or any Kaufman subtest ever excluded from a test battery because it yielded sex differences. And no item on any subtest was ever removed because one group scored higher than the other group on it; they were only removed when they were biased against one group or the other based on its relative rank within a subtest for one group versus another. 4. Wechsler, Binet, and Terman clearly tried to minimize sex differences in their selection as well as exclusion of both subtests and items that produced sex difference. That procedure only applied to the old tests, prior to 1974. Such a procedure was not used for any Wechsler or Binet scale for nearly a half century. 5. There are way more tests than just the Wechsler or Stanford-Binet series. None of the newer group of tests have used that old-fashioned, indefensible approach—not the Kaufman tests, not the Woodcock-Johnson, not the DAS or the CAS or the RIAS.