
How much should we trust medicine?
Review of Medical Nihilism (Jacob Stegenga)

There’s a few main types of broad-side science criticism:
Lowbrow religiously motivated typically focused on denial of biology (evolution) but sometimes expanding widely
Verbal tilt philosophy, usually some brand of social constructivism or more rarely scientific anti-realism or global epistemic skepticism
Schizophrenia-like conspiracy theories, usually in conjunction with Big Pharma Bad content, but also Moon Landings and 9/11 etc.
Scientific skepticism, exploring the limits of science using science
The above are generalized anti-science stances that more or less involves claims that (large parts of) science can’t produce reliable knowledge due to various limitations. Here I want to focus on the 4th option, which is usually grounded in meta-scientific (science of science) research plus some added philosophy. Jacob Stegenga has written a book on the topic which I will review in this post (Medical Nihilism, 2018).
How does one argue that most of medicine is untrustwrothy, or that “we should have little confidence in the effectiveness of medical interventions” as the author puts it? Well, Stegenga tries to accomplish this in only 242 pages in these chapters:
1. Introduction
Part I. Concepts
2. Effectiveness of Medical Interventions
3. Effectiveness and Medicalization
4. Magic Bullets
Part II. Methods
5. Down with the Hierarchies
6. Malleability of Meta-Analysis
7. Assessing Medical Evidence
8. Measuring Effectiveness
9. Hollow Hunt for Harms
Part III. Evidence and Values
10. Bias and Fraud
11. Medical Nihilism
12. Conclusion
The main approach is this:
To evaluate medical nihilism with care, toward the end of the book I state the argument in formal terms. A compelling case can be made that, on average, we ought to assign a low prior probability to a hypothesis that a medical intervention will be effective; that when presented with evidence for the hypothesis we ought to have a low estimation of the likelihood of that evidence; and similarly, that we ought to have a high prior probability of that evidence. By applying Bayes’ Theorem, it follows that even when presented with evidence for a hypothesis regarding the effectiveness of a medical intervention, we ought to have low confidence in that hypothesis. In short, we ought to be medical nihilists. The master argument is valid, because it simply takes the form of a deductive theorem. But is it sound? The bulk of this book argues for the premises by drawing on a wide range of conceptual, methodological, empirical, and social considerations.
Thus, it is a straightforward empirical attack grounded in Bayesian reasoning. Due to various factors, scientific findings are often unreliable and biased, so the amount of justification some scientific evidence provides is less than it appears. On top of that, most evidence is not very informative about causality (’correlation is not causation’).
Stegenga takes care to distinguish himself from the other types of critics mentioned above:
My position should not be interpreted as antithetical to evidence-based medicine, or as supportive of other critical views of medicine. On the contrary. The medical interventions that we should trust are those, and only those, that are warranted by rigorous science. The difficulty is determining exactly what this appeal to rigorous science amounts to, which is why medical nihilism is a subject for philosophy of science. Views similar to medical nihilism are shared by a cluster of critical perspectives on medicine, such as those of the antipsychiatry movement, religious opposition to particular medical practices, and the holistic and alternative medicine movements. I do not align myself with these views. Taking a critical position toward medicine does not imply an alignment with other positions critical of medicine. Indeed, most of my arguments apply to many of these movements more strongly than they do to medicine itself.
As usual, I will highlight paragraphs of interest and add my comments.
First, bringing us back to my controversial post about homosexuality, the book has a rather straightforward discussion of the various concepts of what a disease is (Boorse (1977)):
There are several classes of objections to naturalist accounts of health and disease. One is that it fails to track the way that conditions have been historically classified as disease. A stock example is that of homosexuality, which was long considered a disease, yet now it is not. This change, critics note, was not due to progress in knowledge of biological function or knowledge of the constitutive causal basis of the condition, but rather was due to a change in societal values. To such a line of criticism, though, a naturalist has a straightforward rejoinder: naturalism is based on a conceptual analysis of disease, rather than a historically accurate description of the way particular conditions were in fact categorized as disease.8 Naturalism shows precisely what was wrong with ever thinking that homosexuality is a disease (namely, that homosexuality does not involve a reduction of biological function below typical efficiency).9
9 However, according to Boorse’s account, homosexuality is in fact considered a disease, because it interferes with reproduction. Boorse noted that because his theory of disease is non-normative, the fact that homosexuality is a disease according to his theory does not entail that it is a bad state or that it should be treated. Regardless, naturalism is not committed to an evolutionary account of function. And certainly according to hybridism (see §2.4), homosexuality is not a disease.
The deeper question that Scott Alexander, Bryan Caplan and myself didn’t cover in our exchanges on whether homosexuality is a mental illness (and also transsexuality and so on), is the more general concept of disease or disorder. While we have many obvious examples of these involving physical ailments, perhaps only a minority of diagnoses are of the crystal clear sort:
Influenza, various symptoms, caused by infection of a virus (unsurprisingly called Influenza)
However: most ‘influenza’ infections (influenza-like illness) are not caused by influenza virus (only about 14%!) but various other virusses and other pathogens
Diabetes, insulin deficiency
However: comes in many types which aren’t even that similar in the exact mechanism or treatment
Down syndrome, too many copies of chromosome 21
However: it is possible to have a partial extra copy of chromosome 21, and different people have different version of the partial copy leading to heterogeneity in symptoms; additionally, the extra copy may only be present in some tissues (mosaicism)
Some diagnoses are clearly not like this. For instance, I recently discussed SIDS, which “requires that the death remain unexplained even after a thorough autopsy and detailed death scene investigation.”, which can’t be a definite type of disease or disorder at all.
Stegenga outlines 4 varieties of disease concepts:
A widely held view is that health is a naturalistic notion, construed as normal biological functioning, and disease is simply departure from such normal functioning. Alternatively, many hold a normative conception of health and disease, which claims that health is a state that we value and disease is simply a state that we disvalue. A third approach is a hybrid view, which holds that a disease has both a biological component and a normative evaluation of that biological component. A fourth major approach is eliminative, which claims that the general notion of disease should be replaced by physiological or psychological state descriptions and evaluations of such descriptions. I will call these, respectively, naturalism, normativism, hybridism, and eliminativism. A rich literature has formulated numerous considerations for and against these accounts of disease. In what follows I highlight the central issues dividing these approaches, show that these different conceptions of disease have different implications for determining what counts as an effective medical intervention, and ultimately defend hybridism and a corresponding theory of effectiveness.
I am in the naturalism camp, as I don’t think we should have concepts about biology that depend on the current thing opinion in a given human culture.
Stegenga spends a while attacking the versions he doesn’t like. Naturalism has various issues to be sure. One philosopher formulated naturalism this way:
(1) The reference class is a natural class of organisms of uniform functional design; specifically, an age group of a sex of a species.
(2) A normal function of a part or process within members of the reference class is a statistically typical contribution by it to their individual survival and reproduction.
(3) Health in a member of the reference class is normal functional ability: the readiness of each internal part to perform all its normal functions on typical occasions with at least typical efficiency.
(4) A disease is a type of internal state that impairs health, i.e., reduces one or more functional abilities below typical efficiency.
These various conditions are meant to avoid certain counterexamples. For instance, any reliance on statistical facts about functioning are open to hypothetical situations where somehow everybody minus 1 person in some population at some time got infected by the same virus, this would then become the normative state and thus be could considered the healthy state. There are in fact historical cases that aren’t too far from this scenario (having any form of herpes is 60-95% of the world population, and we have no effective treatment for this).
I think in general the statistical approach is best avoided, and one should instead define it in terms of teleology, that is, biological purpose or function. While evolution isn’t a conscious process, evolution does design things with functions we can sometimes figure out. For instance, the function of the heart is to move blood around in the body. If it stops doing so, you quickly die. The purpose of the immune system is to fight off pathogens (e.g. common cold) and internal threats (e.g. cancer), and you won’t live long without this functionality in place. Everything else designed by evolution has functions too, though we can not necessarily figure out what it is (and sometimes there isn’t any because it’s a remnant, say, the appendix in humans). The particularly murky area is the brain. The purpose of the brain is to control behaviors. Insofar as we can admit that some brains do this worse than others, and some do it very poorly (e.g. mental retardation), we can talk about diseases of the brain. Since the brain is complex, it is not surprising that the ways it can go wrong are also often complex. We may think of failures to properly regulate emotions, sustain concentration, reason, etc. as failures of the function of the brain. Along these lines, the two most basic goals of an animal is survival and reproduction. If the brain is somehow incapable of these (extreme risk taking; non-fecund sexual targets), this can be considered a failure to function correctly. The main function of sexual desire is reproduction, and since sexual desire for the wrong group of people (or not even people) doesn’t lead to reproduction, this is quite a big failure of the evolved function. As can be seen from the quote above about homosexuality as a disease, my view is hardly unusual here, but more or less matches what a philosopher wrote ~50 years ago.
Concerning causality:
An older tradition of evidence in medicine, associated with the epidemiologist Sir Bradford Hill, provides a more compelling way to consider the variety of evidence in medical research. Hill was one of the epidemiologists involved in the first large case-control studies during the 1950s that showed a correlation between smoking and lung cancer.19 The statistician Ronald Fisher had noted the absence of controlled experimental evidence on the association between smoking and lung cancer. Fisher’s infamous criticism was that the smoking-cancer correlation could be explained by a common cause of smoking and cancer: he postulated a genetic predisposition that could be a cause of both smoking and cancer, and so he argued that the correlation between smoking and cancer did not show that smoking caused lung cancer. The only way to show this, according to Fisher, was to perform a controlled experiment; of course, for ethical reasons no such experiment could be performed. Hill responded by appealing to a plurality of kinds of evidence that, he argued, when taken together made a compelling case that the association was truly causal.
The evidence that Hill cited as supporting this causal inference was: strength of association between measured parameters; consistency of results between studies; specificity of causes (a specific cause has a specific effect); temporality (causes precede effects); a dose-response gradient of associations between parameters; a plausible biological mechanism that can explain a correlation; coherence with other relevant knowledge, including evidence from laboratory experiments; evidence from controlled experiments; and analogies with other well-established causal relations.20 Hill considered these as inferential clues, or as epistemic desiderata for discovering causal relations. Although Hill granted that no single desideratum was necessary or sufficient to demonstrate causality, he claimed that jointly the desiderata could make for a good argument for the presence of a causal relation.21 The important point for the purpose of contrast with meta-analysis is the plurality of reasons and sources of evidence that Hill appealed to.
Hill was right, inferring causality is best done by relying on multiple lines of evidence, especially in cases where strong controlled experiments cannot be done (say, we can do them on mice, but not humans). A fun fact here is that Fisher’s interest in the genetics of lung cancer and smoking led to the creation of the Swedish twin register in the 1960s and after about 50 years (Hjelmborg et al 2015), this is what they have found:
Twin pairs discordant for both lung cancer and smokingstatus at baseline are informative for causal analyses. In the lung cancer and smoking doubly discordant pairs, the pairwise relative risk for lung cancer was 5.4 among ever smokers in MZ pairs. It is of historical interest that after the landmark papers of Doll and Hill26 and Wynder and Graham27 in the early 1950s, the causality of the relationship between smoking and lung cancer was soon challenged by the great statistician Ronald Fisher.25 He pointed out the greater similarity of MZ versus DZ pairs for smoking, and indicated genetics as a potential confounder. MZ pairs discordant for smoking would help to resolve the issue of causality. Following up on prior twin studies of smoking discordant pairs,28 29 we can now finally put this issue to rest, an issue debated for many years because of the tobacco industry’s prolonged refusal to acknowledge publicly that smoking causes lung cancer.
This is a follow-up study on the first study using the Swedish twin register which noted “The study of smoking and health was a major goal when compiling the Swedish Twin Registry” (Floderus & Friberg 1988). More fun is that the twin study was financially supported by the “Council for Tobacco Research, USA, Inc.”. This is in fact the Big Tobacco lobby organization trying to prove cigarettes don’t kill you, and I guess they ended up paying for research showing that cigarettes can kill you (cf. Thank you for smoking).
Regarding meta-analysis:
Nevertheless, the general epistemic importance given to meta-analysis is unjustified, since it is so malleable: meta-analysis allows unconstrained choices to influence its results, which in turn explains why the results of meta-analyses are unconstrained. The upshot, one might claim, is merely to urge the improvement of the quality of meta-analyses in ways similar to that already proposed by evidence-based medicine methodologists, in order to achieve more constraint. However, my discussion of the many particular decisions that must be made when performing a meta-analysis indicates that such improvements can only go so far. For at least some of these decisions, the choice between available options is arbitrary; the various proposals to enhance the transparency of reporting of meta-analyses are unable, in principle, to referee between these arbitrary choices (in Chapter 7 I argue that this is the case for many aspects of medical research generally).
Yes, but there is a standard method for dealing with this problem too: sensitivity analysis. For meta-analysis specifically and science in general, one can in theory specify every methodological decision and compute the results for all of their combinations. This has become somewhat popular in recent times (multiverse meta-analysis / specification curve). I previously discussed the case of applying this method to the question of the relationship between brain volume/size and intelligence. It produced this plot:
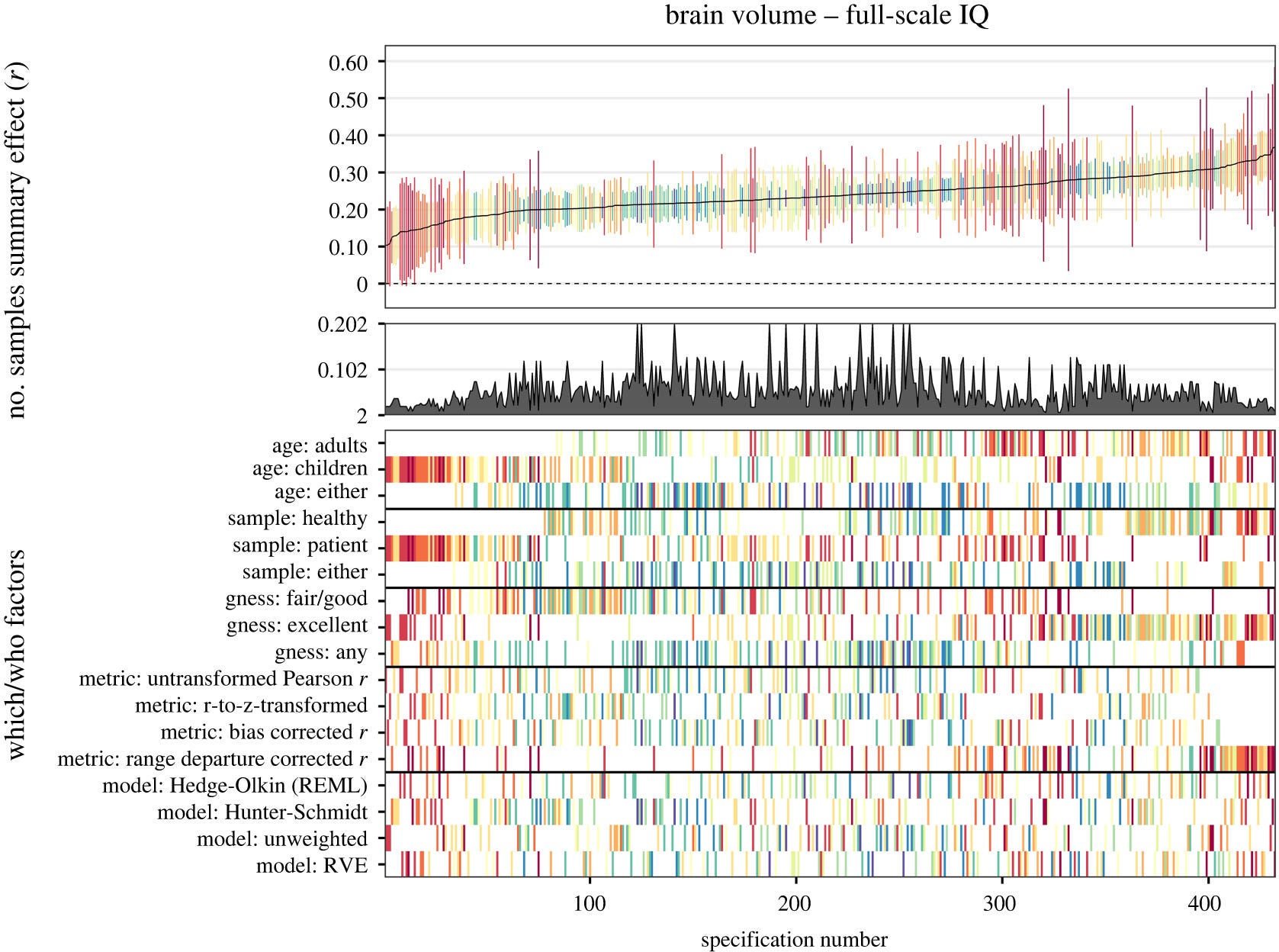
Each column is a combination of methodological decisions, in total about 430. The results in the top part show what the correlation is under different decisions, that is, the correlation ranges from 0.10 to 0.35 or so. One can dig further into these choices to learn why some of them lead to this or that relatively weaker or stronger pattern. Thus, the worry about methodological choices in science and meta-analysis is not insurmountable.
Regarding interactions:
Here is another expression of SEU, again from the evidence-based medicine community: “results of randomized trials apply to wide populations unless there is a compelling reason to believe the results would differ substantially as a function of particular characteristics of those patients.” Similarly, an epidemiology textbook notes that “generalizing results obtained in one or more studies to different target or reference populations [is] the premier approach that public health professionals and policy makers use.” One of the highest-profile guidance statements from methodologists in evidence-based medicine reiterates this view: “therapies (especially drugs) found to be beneficial in a narrow range of patients generally have broader application in actual practice.”16 The trouble with this claim is that, ironically, the ‘evidence base’ for it is extremely thin. Many of the articles that this group cites in support of this claim are merely opinion pieces in medical journals; the more rigorous empirical studies that they cite conclude that SEU is in fact problematic.17 This defense of SEU is remarkable for its violation of its own evidence base.
Stegenga spends quite a bit of time on the extent to which we can generalize findings. In general, people who do randomized controlled trials for medicine make various exclusions which renders the population they study different from the real-life population of those who would receive the medicine (that is, if it works at all). In general, many of these exclusions are sensible: avoid pregnant women (in case the medicine is dangerous to the fetus), avoid people with too many other problems (I guess they might die of something else, or have unforeseen drug interactions), and age limitations (experimental medicine tested on adults before children). However, if one believes that the true effect size of some treatment can vary dramatically between patients, then this kind of selection bias in the samples of randomized trials can be very problematic. To the extent one believes this, it is unwise to just generalize the results from such studies.
I think, however, that the evidence for such interaction effects is quite weak in general. And in general, if such interactions exist, they are very difficult to detect and certainly it cannot be done from casual observation or self-experimentation except in the easiest of cases (e.g., apply the cream to half your face, or the sun). So I don’t think this is a big worry. Occasionally a given treatment works very differently for some patients, usually because they are intolerant of the drug. Even in this case, though, it is not that the antibiotics don’t kill bacteria, just that the patient has a particularly strong side-effect, so it isn’t even a treatment interaction in the strict sense. Antidepressants provide us with another example:
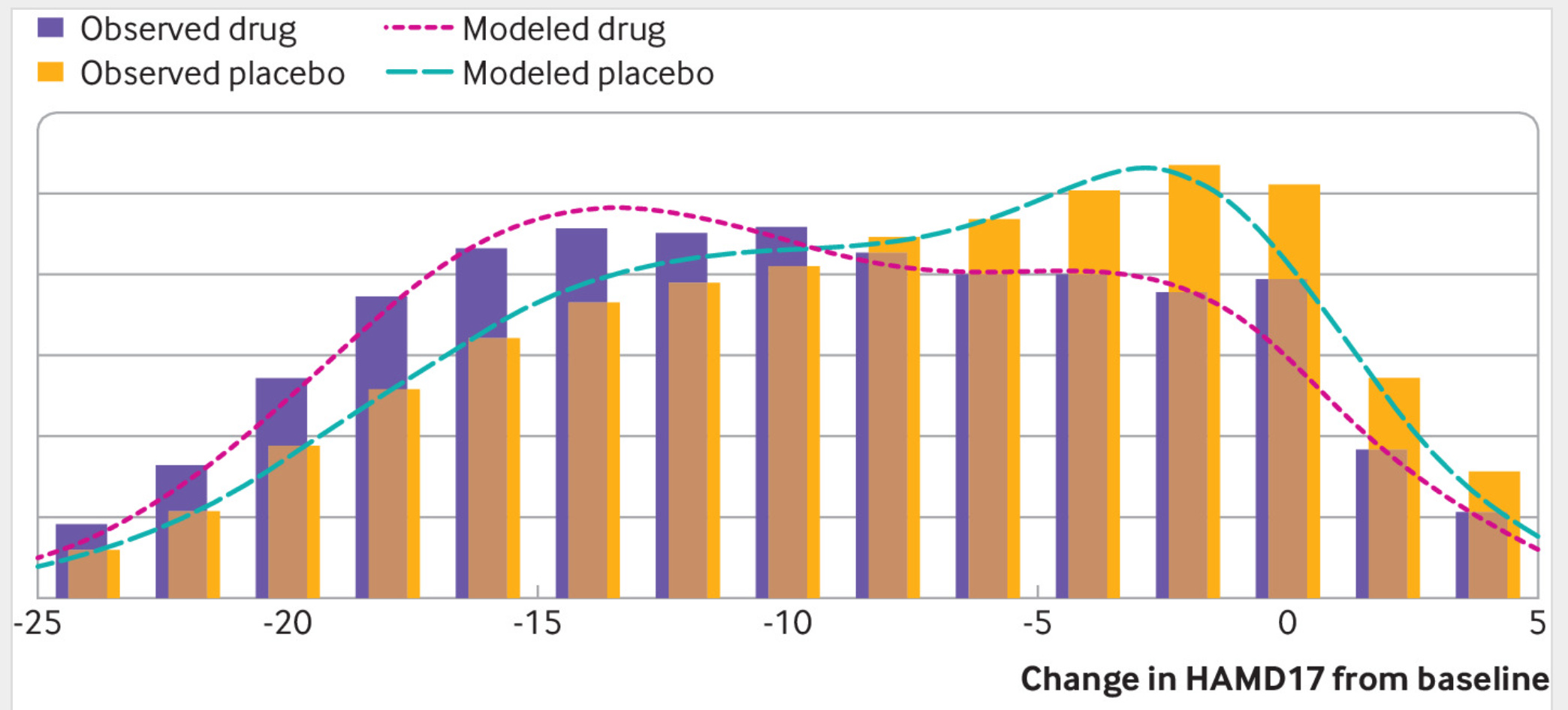
The distributions show the scores on a depression questionnaire in randomized trials with antidepressants vs. placebo. There is a slight difference in the distributions, which comes down to a mean difference of 1.75 points, corresponding to a Cohen’s d of about 0.23. If antidepressant work differently for some people, the distribution of scores in the treatment group should be wider. Hypothetically, maybe some subset of people benefit 2 points, and others have -2 benefit (harm). Thus, the treatment group should have a greater variation if there exist such interactions. Looking at the above distribution, this doesn’t appear to be the case.
However, the bigger problem is this:
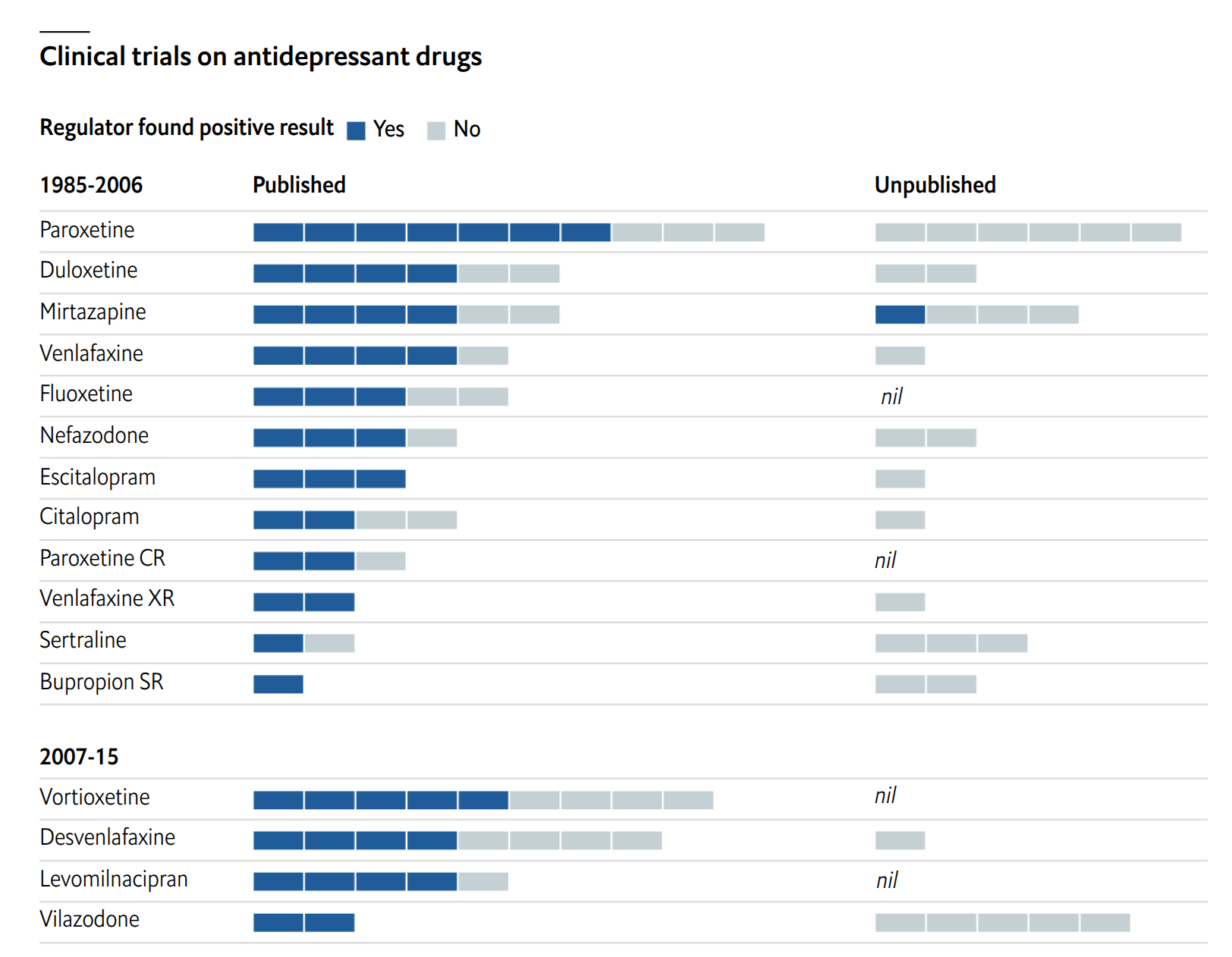
We have known for decades that scientists don’t generally publish negative/null findings, so the published research ends up painting an overly rosy picture. In some cases, it is possible to track down every study that was done, usually because of the regulatory paperwork that was filed. In these cases, one can compare the findings from published vs. unpublished work, which commonly looks like the above. This kind of research is in my opinion the best kind of evidence against medicine in general. For most treatments, there are only a few, maybe 5, studies published ever. Maybe they look good. However, there is the nagging worry that there might exist another 5 studies that look equally good that we simply can’t see because they weren’t published. There is no way to know whether such studies exist or not. Thus, even in the case when we have a half-decent meta-analysis, we have doubt, possibly a lot of doubt, about a given treatment. These problems are tractable, for instance, with regulations stipulating that publication is mandatory (what sensible government would fund research that no one can ever read and learn from?).
Overall, I agree with the book in general due to the above kind of evidence, but disagree with many specifics. It’s a quick but interesting read.
I’d extend your frame one layer down — from epistemic reliability to systemic energy flow. Scientific unreliability isn’t just noise in the data; it’s the steady-state output of institutions optimizing for exergy throughput under asymmetric incentives.
Once you model pharma, academia, and regulation as dissipative control systems rather than neutral truth engines, patterns like thalidomide, specialty-drug patent-extension combos, or DARPA’s dual-use biomedical programs stop looking like isolated moral lapses and start reading as structural feedback loops. The profit function rewards transient efficacy signals, not long-horizon stability, so the weighting between benefit, chronic side effect, and negative counterfactual is systematically skewed.
In short: the bias is thermodynamic, not merely statistical — energy follows the incentive gradient, even when it flows through Bayesian priors. Even clinical trials select for deception — participants routinely downplay side effects or conceal medical history to stay eligible, turning the evidence base itself into a performative energy market rather than a truth engine. The concept of “evergreening” (making small changes, new formulations, combinations, or regulatory strategies to extend patent life) is well known in pharma criticism literature (though not always legally or scientifically indefensible). The case of thalidomide → Revlimid is one of those.
The tobacco case Emil cites was detectable only because of its massive effect size, ubiquity, and temporal duration; many pharmaceuticals have more modest effect sizes, shorter timeframes, or heterogeneous populations, making distortions from deception or structural bias more influential.
https://ijb.utoronto.ca/news/inside-canadas-exploitative-clinical-trial-industry-where-study-participants-say-theyre-incentivized-to-lie-even-about-medications-side-effects/ https://www.astralcodexten.com/p/your-review-participation-in-phase/comments
If Mr. Stenenga's appendix ruptures, or his child comes down with meningococcal meningitis, I certainly hope he avoids medical care.