
How to do a meta-analysis of Black-White IQ gap

https://twitter.com/HoustonEuler/status/837894199814955008
There's been some talk about whether the SIRE (self-identified race/ethnicity) gaps are closing and if so how much and when they did that. The matter is complicated for many reasons. The last major, published review is very dated, as it is from 2001.
Roth, P. L., Bevier, C. A., Bobko, P., Switzer, F. S., & Tyler, P. (2001). Ethnic Group Differences in Cognitive Ability in Employment and Educational Settings: A Meta-Analysis. Personnel Psychology, 54(2), 297–330. https://doi.org/10.1111/j.1744-6570.2001.tb00094.x
John Fuerst took a stab at it a few years ago (in 2013), but apparently never finished the project (sound familiar?). I digged up his datafile and plotted it, which looks like this:

The wiggly fit is from LOESS. Both the mean and the median gaps are exactly 1.00. The wiggly pattern is possibly entirely artifactual.
The data are messy. If we take a look at the file, we find:
Meta-analyses of specific, selected groups e.g. criminals reviewed in Shuey (1966) found a gap of 0.73 d data on 46 studies from 1919-1965.
IQ batteries for special contexts e.g. GATB used for employment test. A review found a gap of 0.90 d based on data from 1940-1970.
Standardized IQ batteries e.g. Wonderlic. A review found a gap of 1.00 d based on data from 1970.
Achievement test data for primary education e.g. NAEP. There are many datapoints from this, e.g. one datapoint found a gap of 1.35 using 1970s data and the NAEP LTT.
Achievement test data for tertiary education selection e.g. SAT. For the years 1987-2009, the mean gap was 1.06.
Poor/short tests e.g. WORDSUM (10 items only).
Wiggly patterns can easily arise if the type of test influences the gap size (surely), and the distribution of data sources is not equal across time, which it is very unlikely to be given that there are only some 100 included datapoints.
Going forward
If one wants to properly study the topic, one has to collect a lot of data. The following approach seems reasonable to me. One should collect data from, in order of preference:
All standardized lengthy IQ tests and batteries commonly used in the USA. These include, WAIS, WISC, WPPS, AFQT/ASVAB, DAT, DAS, Wonderlic, PPVT, WJ, Raven's, CCF (Cattell), CAT, GATB, CAB, HB.
All standardized achievement tests and batteries commonly used in the USA. These include NAEP, PISA, TIMMS, SAT, ACT, GMAT, GRE, MCAT, LSAT, WRAT, KAT.
Data from the commonly used/discussed ad hoc/short IQ-ish tests. This is primarily the WORDSUM which has been included in the GSS for many decades.
When collecting data for (1-2), it makes sense to also collect the subtest gaps. These can then be used in a combined analysis for Spearman's hypothesis. One does not need case-level data to do this as Jensen's method does not require this (it has other problems tho). In fact, neither does SEM, but SEM does require that one can estimate a complete correlation matrix. While one cannot find a paper that used every possible test combination (but a good starting point is the MISTRA data), one may be able to find papers that reported every possible two-way pairing which can then be used to build a larger correlation matrix.
Samples
The IQ batteries usually, but not always, have a nationally representative standardization sample. There's usually a such sample for each iteration of the test, which makes it possible to examine historical trends. These are the best source of data for the research questions and one should try to find all of these, as well as contact all the test publishers for any additional data. If they decline, this needs to be noted as well. Note that two samples can both be fairly nationally representative in the broad sense without being entirely equal. As such, even differences in sampling for these can alter results. There is no probably no easy way to deal with this problem.
The achievement tests often have problematic sampling. NAEP has good sampling (everybody in school at age 17 I think?), but may have problems with test cheating related to No Child Left Behind and similar legislation. The tertiary education-related tests (SAT, ACT, GRE, etc.) have self-selected samples and these change over time (more people take the tests now) which affects the observed gaps even if the ability distributions don't change.
Test changes
Another source of trouble is when the test or scoring changes over time. For instance, the NAEP data indicate that the reading gap was 1.31 d in 1980 and then 0.82 d in 1984! Are we to believe that the gap narrowed some .50 d in 4 years?
Since the group differences are a source of embarrassment for many testing companies, they probably took extensive steps to minimizing the gaps (sometimes they are open about this too, and it also applies to sex gaps). While one solution simply involves lowering the g-loading of the test, this will also make the test comparatively less useful (per this study). A better solution is to increase the size of the group factors that the less bright groups are better at. For instance, 2015 evidence indicates that Blacks do relatively better at the non-g memory factor, with an advantage of 0.35 d.
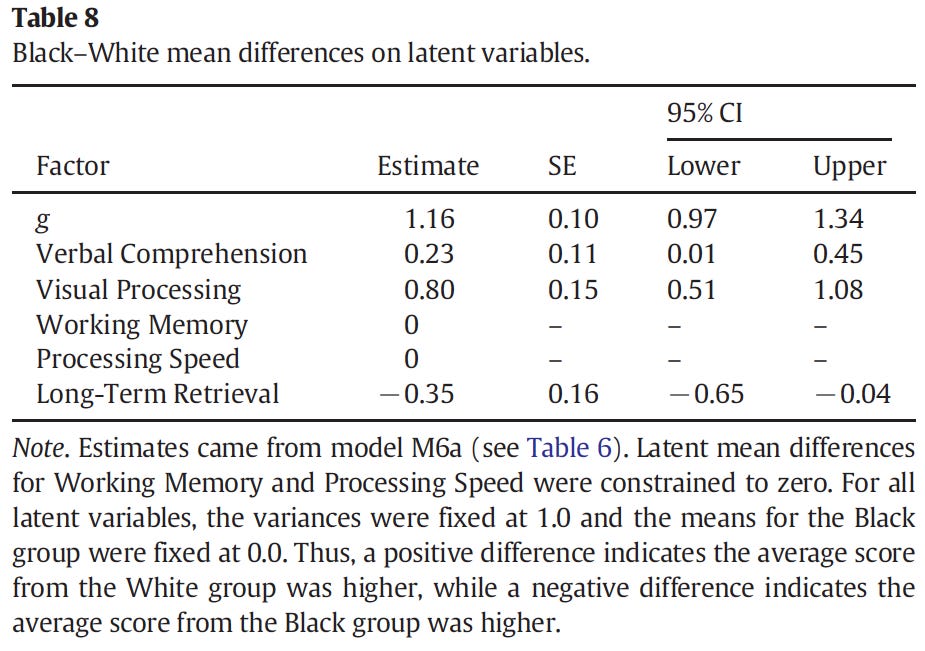
As such, one could swap around some tests in a battery to add more memory factor tests, and one could probably do this without altering the overall test g-loading much. This would then decrease the IQ gap on the test by some amount. In the test above (WAIS-4 + some additional tests), the g-gap was 1.16 while the IQ gap was ??? (not reported).
Beginnings
One can begin using the Dickens and Flynn collection from 2006. It looks like this:
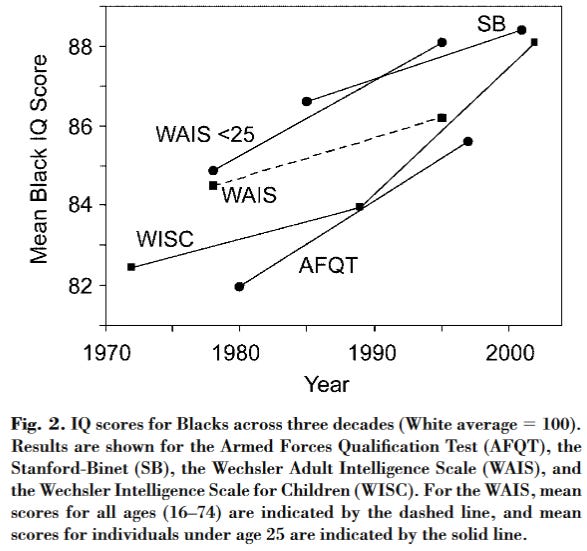
Based on these, it does appear that there are some gains in IQ scores and maybe in GCA -- the underlying ability trait -- as well. Note that the general upwards trend in these data is also found in Fuerst's dataset: look at the period 1970 to 2000 trend. In fact, this is the period with the largest gains, but they don't seem to continue in the post 2000s data, as the trend then moved upwards again (e.g. d = 1.13 in WAIS-4 which is not in the dataset).
Black gains are expected over time given a purely genetic model of differences because of the increased rates of inter-racial marriage which adds more European ancestry to the Black group. This also brings us to the problem of who is included in the Black/African American as well as White categories over time. These problems cannot be solved by such an analysis as this one, but one can solve them using genomic data, which does not care about the SIRE categories. Given a large sample of African Americans (say, n=1000 assuming it is representative), one can regress IQ on African ancestry and look at the predicted mean IQ for a person with 100% African ancestry.