
How to read SlateStarCodex (Scott Alexander) blog

TL;DR tweet version of this post.
The cultural revolution has come to SlateStarCodex (which now also has a Wikipedia page). Journalist is threatening to reveal his real name and endanger his work as a shrink. There are multiple good write-ups:
Scott H. Greenfield - New York Times Killed Slate Star Codex
Robby Soave - The New York Times's Inconsistent Standards Drove Slate Star Codex To Self-Cancel
The censorship of the insane far left is old news at this point. We've been here before, and we cannot learn, so we must do it again. God's punishment to communist atheists is that their countries turn into nightmares repeatedly.
There is even a forecasting question on Metaculus about how likely this doxxing is:
How to read Slate Star Codex
They say the internet never forgets. It's not entirely true, but it usually doesn't forget popular stuff that can be easily backed up (that means static pages, not videos or dynamic pages, see here for case stories of hard-to-find stuff). There's two chief places to go looking for archives:
The Internet Archive's Wayback machine: https://web.archive.org/
the "Archive" site: it's currently at https://archive.vn/ and https://archive.ph/ and some other redirect domains. This service is explicitly censored by Twitter, but they are being lazy about it (for now).
The first one is a long-running organization dedicated to backing up stuff on the internet. It also backs up video content and books (see Gwern's search guide here).
Wayback Machine
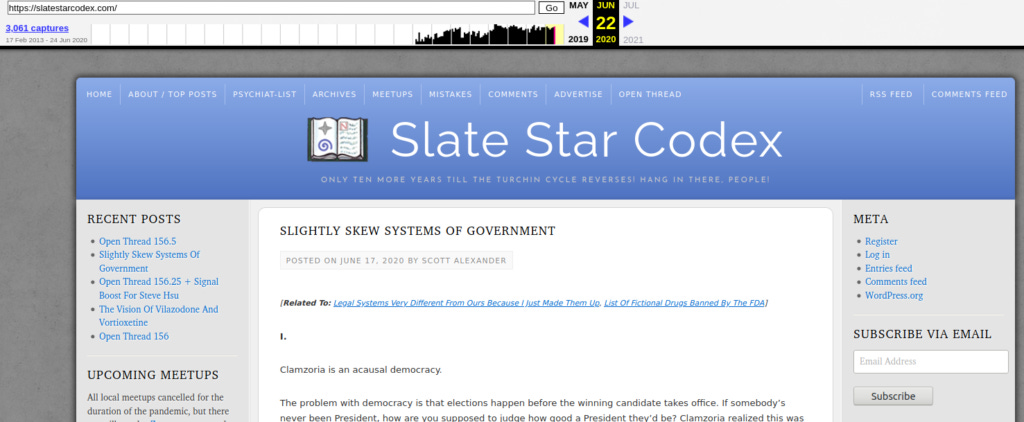
To read the blog, you can simply plug in the URL you want:

These are all the versions of the page backed up. Click any of them you want.
If you get a version you don't like:

Simply try another date for the same page:
OK, what if you don't know what you are looking for exactly? Scott has an archive page and it's archived too:
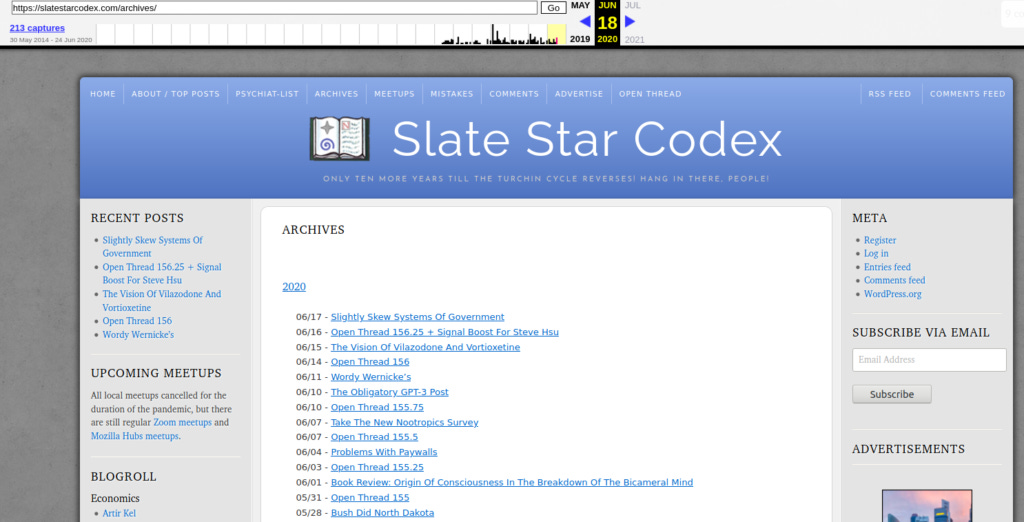
The Wayback Machine creates its own overview page too, called a site map:

Archive
It works the same as above more or less. Plug in a page you want:

As far as I know, it doesn't have a site map, but you can search with a glob to find all the archived pages on the domain. One cannot link to this page because the site removes the "*" (asterisk) in the URL, just type what you see in the screenshot:
