
Motivated reasoning and intelligence
Reanalysis of Kahan et al and replications

Years ago, a very flashy finding by Kahan and colleagues (2017) got popular (1200+ citations). It goes like this, you give people some matrices of fake study data like these:
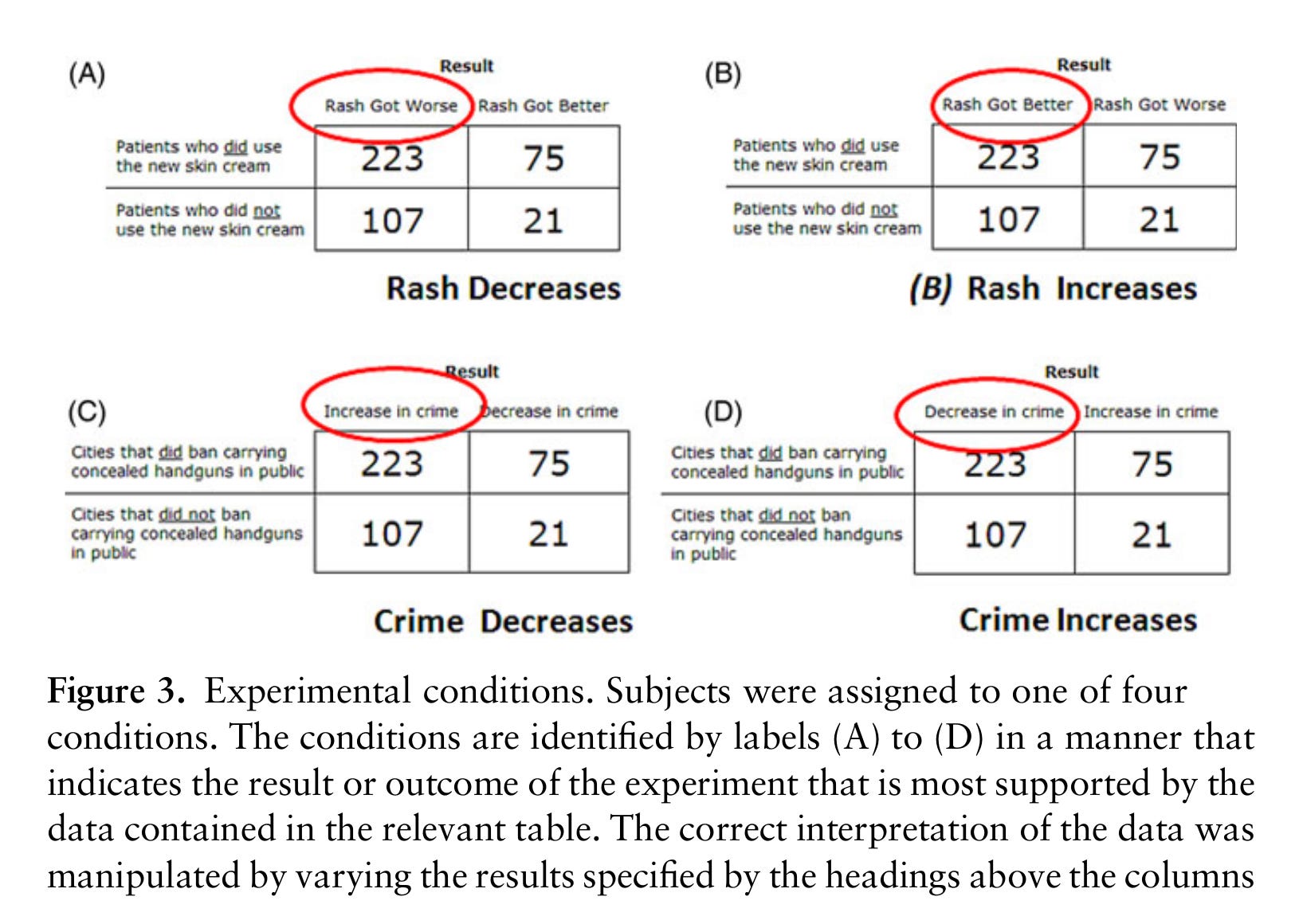
So you tell people that some treatment/policy was given to two groups of people/units. The trick is that these groups are of unequal size, instead of the intuitively expected 50-50% that we usually see in randomized controlled trials. As such, one cannot just look at the counts of units that improved with treatment, one must calculate the fractions and compare those. Doing those numbers in the head is a bit obnoxious, but clearly the 223/75 (2.97 OR) is smaller than 107/21 (5.09 OR). Depending on which labels are put on, then, the subject just has to 1) realize that fractions or odds ratios are to be used, not raw counts, 2) determine which number is higher, and 3) click the right option. In the top left table (A), thus, the hypothetical cream was effective against the rash since the proportion of people who got better is higher. The labels are just for distraction and it’s a relatively simple math question. To do the study, then, you survey some people and give them a random subset of these questions, with labels chosen at random, some political, some not. If you gave them all of them, they would figure out the trick and the study probably wouldn’t find too much of interest. Before giving them these questions, you measure their numeracy IQ and ask their political leanings. Now you are ready to fit some regression models to predict whether a given person solved the trick questions. The way motivated reasoning/Bayesian priors enters the picture is that if people already think the conclusion is true (guns prevent violence, say), then they are probably less likely to double check their math, and thus more likely to make mistakes. For the control condition of the cream and rash (non-political):
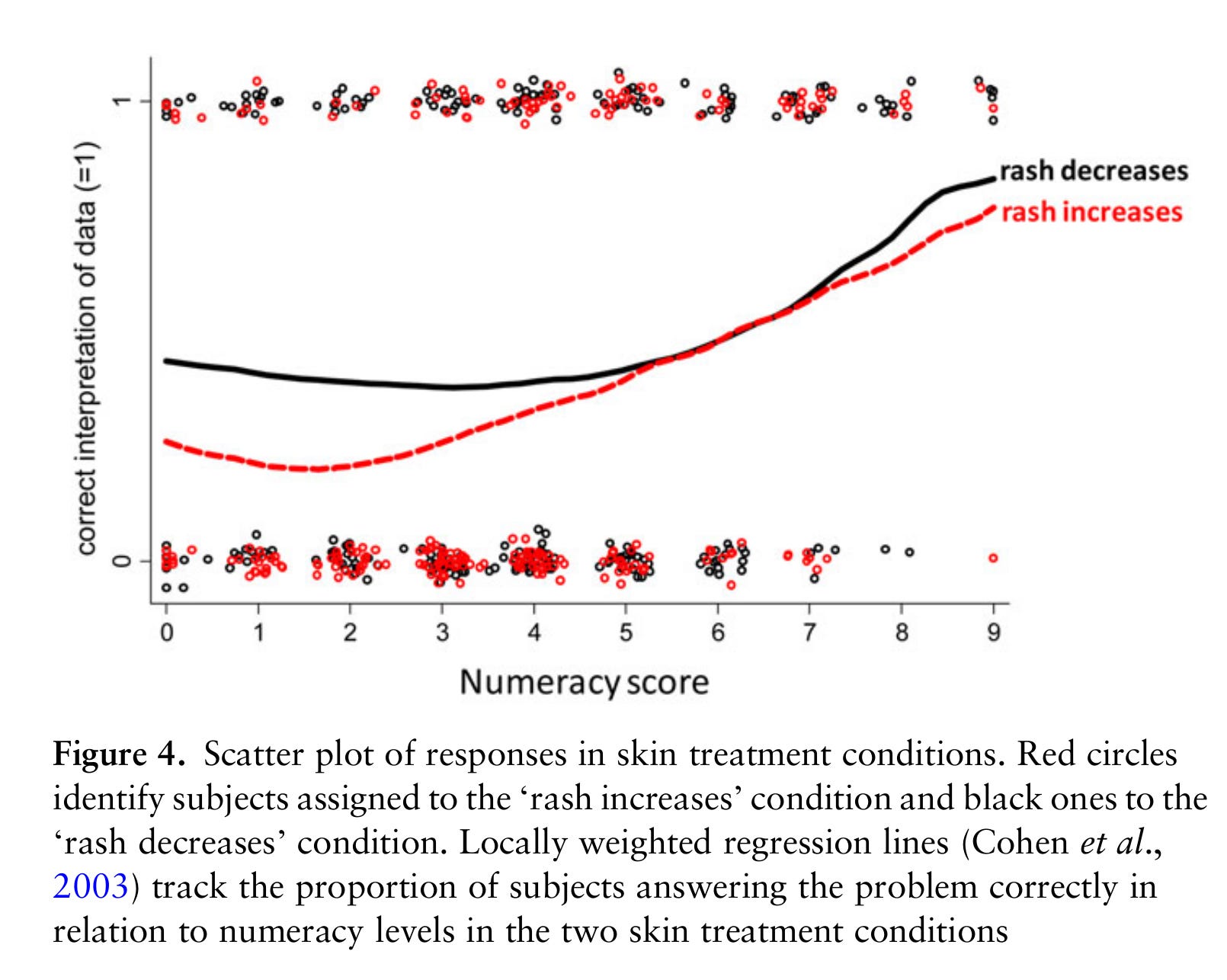
We see the expected effect of numeracy increasing the chances that people get that item right. But what about the political versions?:
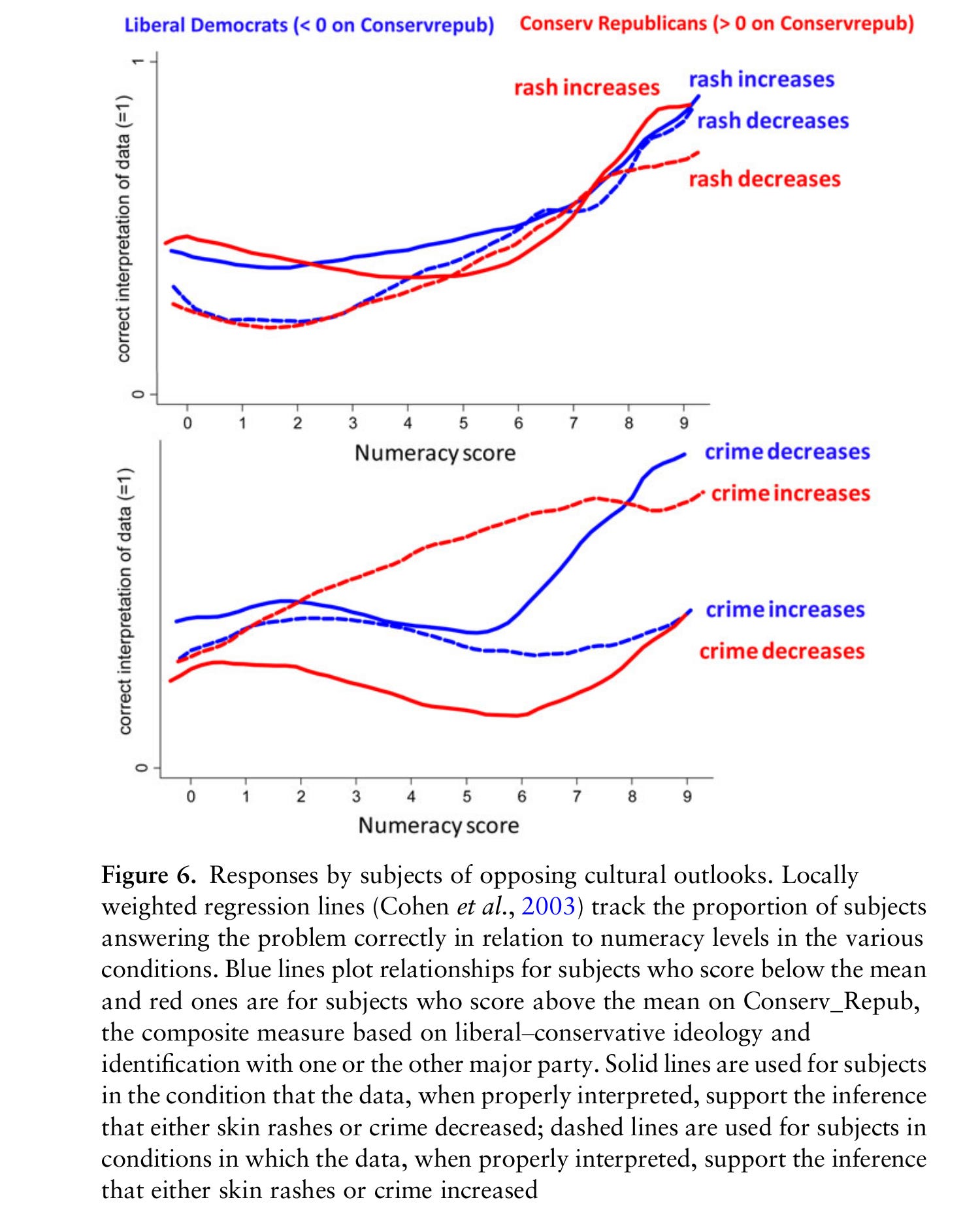
Here they just split the sample in 2 by political leaning (left vs. right). For the gun ban vs. violence, their plot shows that numeracy seemingly does not predict getting the trick question right unless it aligns politically. Thus, it appears both sides have about equal motivated reasoning/Bayesian priors.
So what is the issue? Their sample size is fairly reasonable, 1100 Americans fairly balanced for politics (Yougov data). But there are some replication studies. First Kahan et al published their own n=800 people direct replication in reply to some critics: