
New paper out: Intelligence and General Psychopathology in the Vietnam Experience Study: A Closer Look

Kirkegaard, E. O. W., & Nyborg, H. (2021). Intelligence and General Psychopathology in the Vietnam Experience Study: A Closer Look. Mankind Quarterly, 61(4). https://doi.org/10.46469/mq.2021.61.4.2
Prior research has indicated that one can summarize the variation in psychopathology measures in a single dimension, labeled P by analogy with the g factor of intelligence. Research shows that this P factor has a weak to moderate negative relationship to intelligence. We used data from the Vietnam Experience Study to reexamine the relations between psychopathology assessed with the MMPI (Minnesota Multiphasic Personality Inventory) and intelligence (total n = 4,462: 3,654 whites, 525 blacks, 200 Hispanics, and 83 others). We show that the scoring of the P factor affects the strength of the relationship with intelligence. Specifically, item response theory-based scores correlate more strongly with intelligence than sum-scoring or scale-based scores: r’s = -.35, -.31, and -.25, respectively. We furthermore show that the factor loadings from these analyses show moderately strong Jensen patterns such that items and scales with stronger loadings on the P factor also correlate more negatively with intelligence (r = -.51 for 566 items, -.60 for 14 scales). Finally, we show that training an elastic net model on the item data allows one to predict intelligence with extremely high precision, r = .84. We examined whether these predicted values worked as intended with regards to cross-racial predictive validity, and relations to other variables. We mostly find that they work as intended, but seem slightly less valid for blacks and Hispanics (r’s .85, .83, and .81, for whites, Hispanics, and blacks, respectively).
Keywords:Vietnam Experience Study, MMPI, General psychopathology factor, Intelligence, Cognitive ability, Machine learning, Elastic net, Lasso, Random forest, Crud factor
This is a rather cool paper in my opinion. It illustrates the idea I previously wrote about in this post: Enhancing archival datasets with machine learned psychometrics, and our previous conference presentation at ISIR 2019 (still not published, but this paper contains a summary of it). The main impressive finding is this:
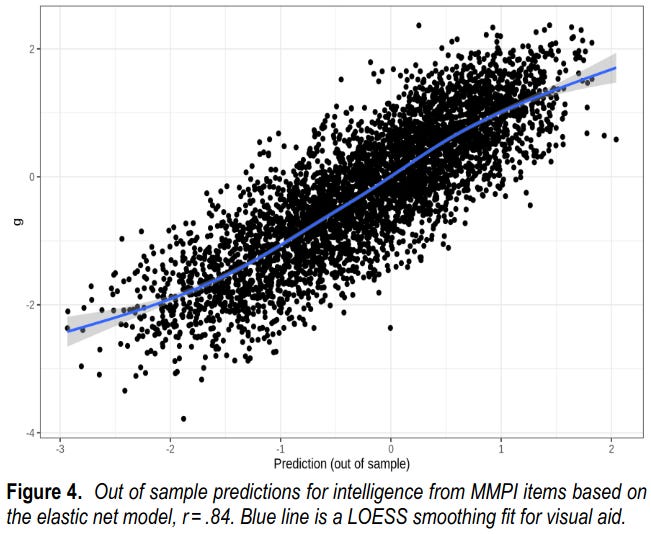
So, using just a bunch of true/false self-report items, one can predict g at r = .84! Jensen's pattern holds too, again, for the P factor loadings, both for scales and items:
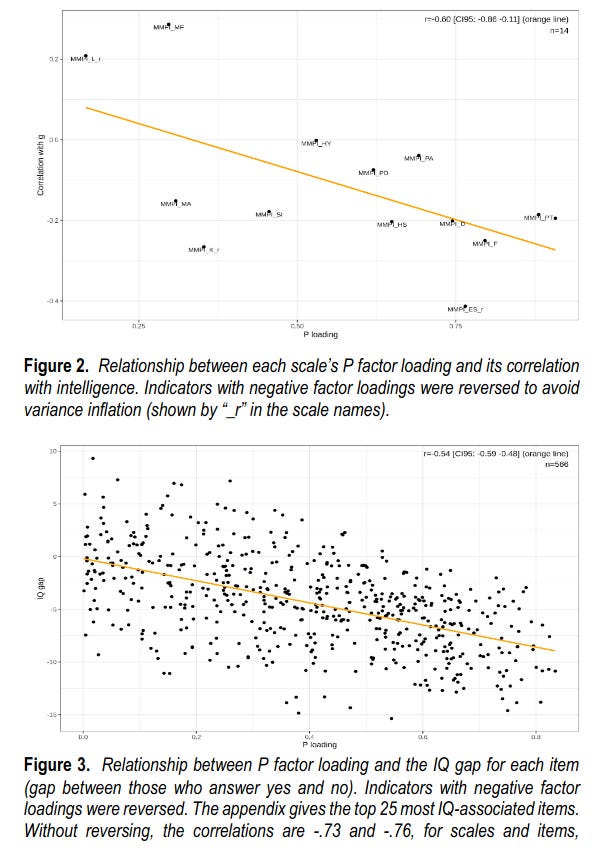
Nevertheless, there is a lot of spread, which one can use to improve the prediction of g. Not that many items are needed to predict well:
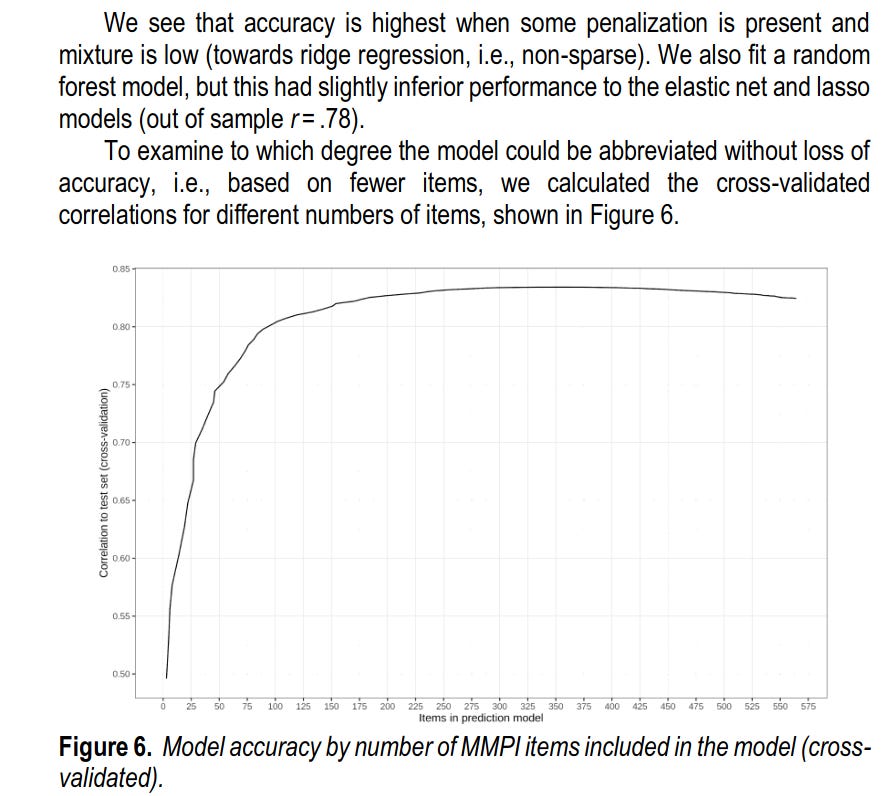
The predicted values of g work as intended, and only suffers small racial bias:
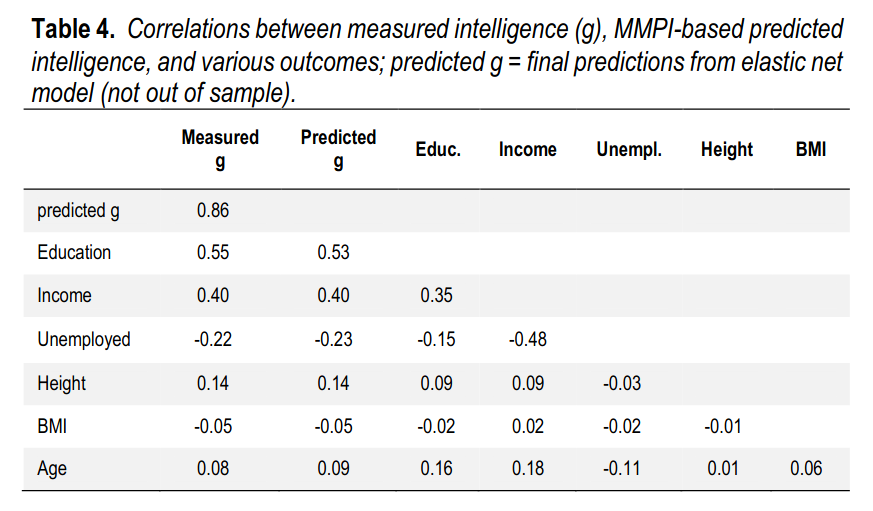
Visually:

So going forward, we need to find out:
Can we find more datasets that have MMPI items and intelligence tests? Public?
Using such datasets, do the predicted/imputed g scores work as expected despite training model on one dataset and using on another?
What factors determine how well this cross-dataset prediction works?
Can we achieve equally impressive results for other datasets that have many varied items?