
Some people have IQs of 160
But technical limitations make it difficult to say who exactly

Erik Hoel recently wrote a piece with a lot of problems: Your IQ isn't 160. No one's is. Since it appears no one has written a reply, I will provide one.
His first point is well taken. If you google any historical genius and ask about their IQ, you will get a lot of fake results. Einstein 160, Hawkings, 170 etc. These values are fake as in literally made to get your clicks. However, there are estimates that aren't made up and have some claim to be taken seriously. It is generally possible to estimate the intelligence of people you know a lot of stuff about, but who never took an IQ test. In fact, sometimes you will want to rely more strongly on the indirect evidence. Here's how he covers Einstein:
But this gives us an easy question: did Einstein and other great geniuses of the past “test well?” If they did, then they probably had a high IQ. This method isn’t perfect, but since we lack any actual IQ data on the majority of historical geniuses, it can at least point us in the right direction. E.g., Einstein
did flunk the entrance exam to the Zurich Polytechnic when he first took it — when he was about 1 1/2 years away from graduating high school, at age 16, and hadn’t had a lot of French, the language in which the exam was given. He did fine on the math section but failed the language, botany and zoology sections, according to history.com. A 1984 New York Times story says that the essay Einstein wrote for this exam was “full of errors” but pointed to his later interests.
And yes, he was taking it in a second language, and trying to get into college early, but still, failing botany and zoology? Just “fine” on the math section? Hard to imagine most AP students now-a-days getting those sort of scores. While we can’t possibly know if the standardized tests at the time are as closely correlated to IQ as SAT scores are today, surely they correlate to some degree?
Theoretically, one could attempt to use such entry scores to estimate Einstein's IQ. It would be difficult considering that we have to take into account that he studied in a foreign language, probably didn't care about botany much (who does?), and was also on the young side. Hoel also looked at Einstein's grades, but grades aren't that strongly correlated with intelligence, so it's unclear why he would do that except for general innumeracy (the paper he cites reports a correlation of about .40, which is strong by social science standards, but weaker than the correlation between height and weight). But we know a lot of stuff about Einstein. For instance, one of his sons was a professor of engineering at Berkeley, which is a very hard position to get into without high intelligence. This isn't generally how historical estimates of intelligence are made, though.
Anne Roe's estimates of elite scientists

Hoel moves on to a more juicy target:
Consider a book from the 1950s, The Making of a Scientist by psychologist and Harvard professor Anne Roe, in which she supposedly measured the IQ of Nobel Prize winners. The book is occasionally dug up and used as evidence that Nobel Prize winners have an extremely high IQ, like 160 plus. But it’s really an example of how many studies of genius are methodologically deeply flawed. In the book, the claims and numbers verge on the obviously ridiculous (e.g., Roe cites someone who claims that Goethe had an IQ of 210, noting that this beat out Leibniz at 205).
What Anne Roe did was make a very high end test as she expected the IQs of elite scientists to be very high. To do this, she collected difficult questions (items) from other tests. To figure how the meaning of the resulting scores, she gave the same difficult test to some PhD students, who also received a standard IQ test. Thus, using the linked tests, one can figure out how far the elite group is above the PhD group, and you already know their IQ because they took a standard IQ test that has general population norms. As such, if the elite group scored 2 standard deviations (d) above the PhD group, and the PhD group scored 2 d above the general population, the elite group will be about 4 d above the general population, i.e., 160 IQ on average. This is essentially the same method that modern researchers use when they link international tests between countries, e.g. PISA to regional achievement tests like TERCE. So if Brazil scores 1 d above Haiti in TERCE, and Brazil scores 1 d below the UK in PISA, then we can estimate that Haiti is about 2 d below the UK. This is how the various international rankings for countries are constructed. An example is that of the World Bank researchers who computed a 'basic skills' index, which I covered recently. So this method is far from being mysterious and is actually common, good practice.
For good measure, let's look at what Roe did in her book. (Gwern has nicely put it online here.) The chapter dealing with this research is just 10 pages, so you can pause the blogpost and read it now. Here's how the constructed the 3 tests:
I have gone into these details to explain why I have used a Verbal-Spatial-Mathematical test, and why I have not combined the scores from all of them into one final, overall score. The test I used is not one that has been used before, at least in this form. When I was planning the study I looked over a variety of standardized tests. (A standardized test is one that has been tried on a population of known characteristics, so that we know what scores to expect on the average, and that has been checked to be sure that it is valid, that is, that it tests what it is supposed to test, and that it is reliable, that is, that you will get the same results if you give it to the same population again. These are difficult technical problems to which a great deal of attention is given.) I could find none that seemed to me to be difficult enough for the group I proposed to test. In psychological jargon, they did not have enough ceiling.
I took my problem to the Educational Testing Service, which, among other things, developed and administers the Scholastic Aptitude Test which many of you have taken as a preliminary to college entrance. After some consultation they pulled out a lot of difficult items from their files and made up the verbal test. The spatial test is part of another test, and the mathematical test is an abbreviation of a special test they constructed for one of the military services during the war. All were given with arbitrarily set time limits.
That's what Hoel's comment about the SAT is coming from. The Educational Testing Service (ETS) is the maker of the SAT, so what they did was look in their files for the hardest verbal items, suitable for a very high range test that she needed. Contrary to Hoel, it is not difficult to figure out the sample sizes of the students or how they were recruited, Roe tells us:
I made an attempt to get some graduate students to take the same test, just as a matter of general interest, but succeeded in getting only 10, and under circumstances which made it impossible to judge how they had been selected. I then dropped the idea of getting any comparison group until it was announced that tests were to be devised in connection with draft deferment. It then seemed to me that I should make some effort to get a reasonably exact idea of just where these eminent scientists stood in the general distribution of intelligence in the population. Such information might be of use,—particularly in determining the level at which exemption might be considered on this basis,—and was not obtainable anywhere else. I had the great good fortune about then to meet an old acquaintance, Dr. Irving Lorge, who came to my rescue and arranged to give the test to all students matriculating at Teachers College, Columbia for a Ph.D. that February. All of their Ph.D. students have to take a battery of tests. This test would be included in the battery. Since the other tests had been well standardized it would then be possible to draw up tables of equivalents by which scores on the VSM could be converted (within certain limits of assurance) to scores on these other tests. This, incidentally, upset my budget considerably.
Edit to add: Hoel is correct that the second sample is what we care about, and the sample size for this is unknown. However, it seems large enough for her purposes because she only needs to estimate the mean and SD in that sample.
Using her student sample as a bridge, she then arrived at these values:
Let us see what these figures mean in other terms. I must caution that these equivalents have been arrived at by a series of statistical transformations based on assumptions which are generally valid for this type of material but which have not been specifically checked for these data. Nevertheless I believe that they are meaningful and a fair guide to what the situation is.
The median score of this group on this verbal test is approximately equivalent to an IQ of 166. The lowest and highest scores would be at about the levels of 121 1Q and 177 IQ. We have already noted that the test was probably not difficult enough for some of these men, hence this estimated upper limit is lower than a more adequate test would give. This would not affect the median score, however.
Now let us look at 1Q’s of college populations of today. Embree found that 1200 high school graduates who went to college had been found during childhood to have a median 1Q of 118; those who graduated with a B.A. an 1Q of 123. Honor graduates had a median IQ of 133 and those elected to Phi Beta Kappa of 137. The range of 1Q’s for all of those who received degrees was from 95 to 180. For persons who went on to take a Ph.D. Wrenn found a median IQ of 141.
It is clear, then, that so far as verbal ability is concerned these eminent scientists are on the average higher than the general run of those that get Ph.D.’s, but, and this is very important, some of them are not as high as the average Ph.D. It is, then, not essential to have this ability at the highest level in order to become an eminent scientist. That it is doubtless a great help is another matter, but it should be remembered that it is less helpful in some fields than in others.
She then did the same thing for her spatial test:
These scores can also be translated, as were the scores on the verbal test, into approximate IQ terms. The lowest score, in these terms, is about the same as the lowest score on the verbal test; it gives an IQ equivalent of 123. The highest score on this test, however, does not quite reach the median score on the other, being equivalent to an IQ of 164, while the median IQ on this test is 137. This means that, as compared to Ph.D. students these men do not score as much higher on this test as they do on the verbal test. But there is a catch here. That is the correlation of this test with age which is —.40. That means that the younger the man the more likely he is to get a high score on this test. If these men had been tested 20 years earlier they might have scored as much higher on this test as they did on the other.
Note the age bias, which makes it difficult to say exactly what the true score might be, but the median was 137, which is very high indeed. We could guess that perhaps 10-20 points have to be added to this for the age confounding, which would move the estimate to the 147-157 IQ region. Her math test was uninformative because the hard scientists scored near the ceiling, so it cannot provide us with any estimates. Very difficult math tests rely heavily on taught materials, and it's unlikely that the psychologists or biologists would be familiar with the math used in the test, even if they were very smart. One has to use a different approach, probably a speeded test of mental math (again, assuming people didn't spend time learning mental tricks to do these).
Looking back at Hoel's claims, we are not particularly amused:
Yet, Roe never used an official IQ tests on her subjects, the Nobel Prize winners. Rather, she made up her test, simply a timed test that used SAT questions of the day. Why? Because most IQ tests have ceilings (you can only score like a 130 or 140 on them) and Roe thought—without any evidence or testing—that would be too low for the Nobel Prize winners.
Roe could not use a standard test because the ceiling was too low. Her assumption about their extreme level of intelligence was verified by her research. Even her original 50 item extremely difficult verbal test was found to be too easy so she had to add another 30 items.
Can you believe how easy this item is? Not understanding the Flynn effect
Hoel's next comment shows further ignorance of the topic:
Perhaps these SAT questions were just impossibly hard? Judge for yourself. Here’s one of the two examples she gives of the type of questions the Nobel Prize winners answered:
In each item in the first section, four words were given, and the subject had to pick the two which were most nearly opposite in meaning and underline them.
Here is one of the items: 1. Predictable 2. Precarious 3. Stable 4. Laborious.
This. . . isn’t very hard (spoiler: 2 & 3). So the conclusion of a median verbal IQ of 166 is deeply questionable, and totally reliant on this mysterious conversion she performed.
Verbal tests like synonyms and antonyms have very strong Flynn effects, so if they seem easier to you now, that is because they are. You are fortunate to live 60+ years in the future! Here's some Flynn effect numbers on tests from Flynn himself (2010). These are for the WISC, a children's test, we would prefer the WAIS, but I couldn't find right right now. I think they are quite similar anyway.
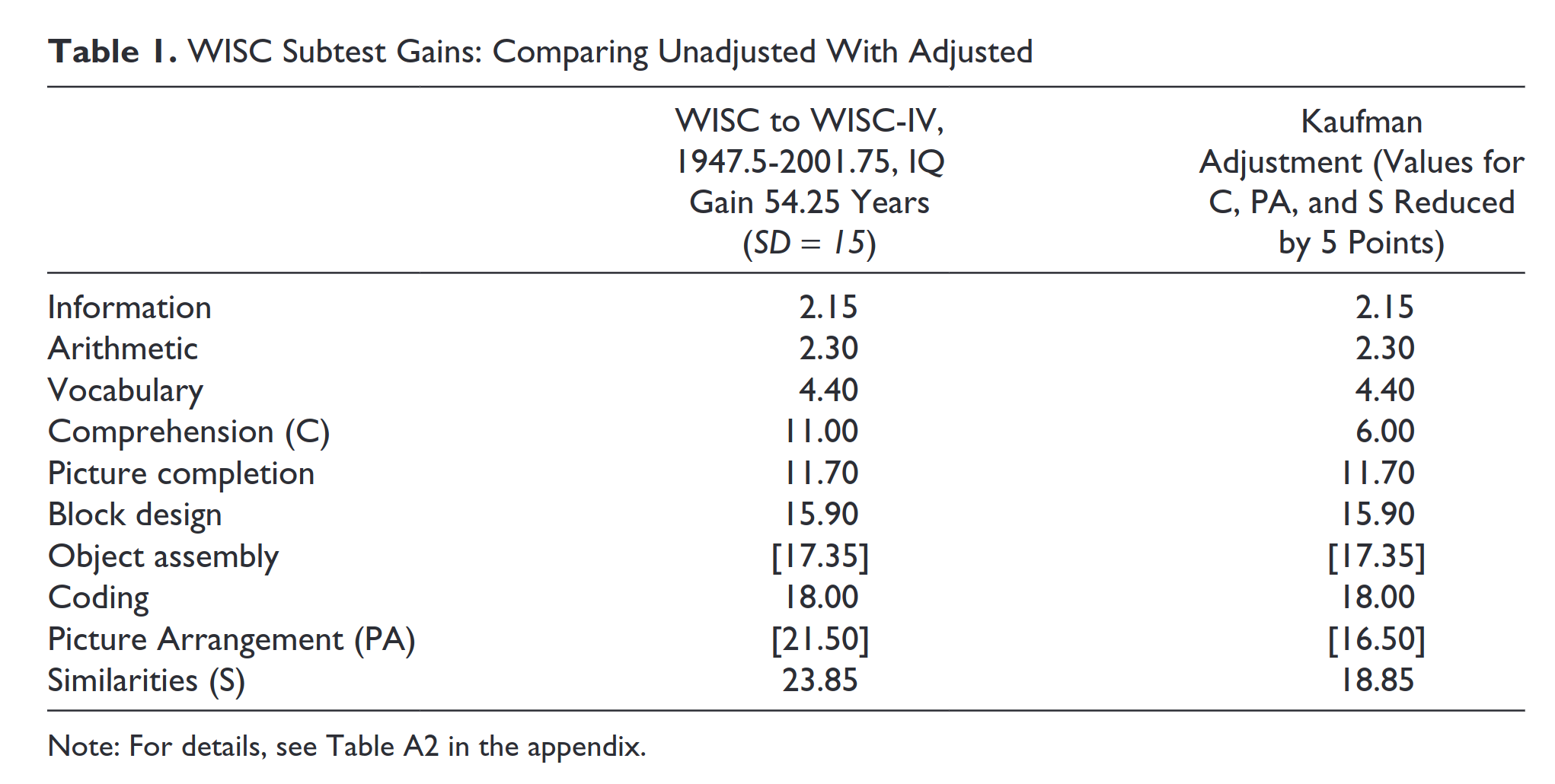
So over a period of 54 years, there was a Flynn effect of some ~20 IQ depending on whether you use Flynn's or Kaufman's values. That's about the same period since Roe's study, so that means that a test item has gotten about that much easier over time. This would move an item designed for 130 IQ to 110 IQ.
Hoel continues:
This sort of experimental setup would never fly today (my guess is the statistical conversion had all sorts of problems, e.g., Roe mentions extraordinarily high IQ numbers for PhD students at the time that don’t make sense, like an avg. IQ of 140). A far more natural reading of her results is to remove the mysterious conversion and look at the raw data, which is that the Nobel-prize-winning scientists scored well but not amazingly on SAT questions, indicating that Nobel Prize winners would get test scores above average but would not ace the SATs, since the average was far below the top of the possible range.
Entirely incorrect. There is nothing wrong with the setup. Hoel fails to understand the whole of the Flynn effect. The scientists did unusually well on the tests, which is why she had to go out of her way to make extra special difficult tests. IQ's of 140 for PhD students make a lot of sense at the time. Hoel fails to understand that university uptake has gotten much, much less selective. As such, the average IQs of people with various degrees is now much lower than it used to be.
Reliability as function of intelligence
Hoel's next point is entirely correct. You should be very skeptical of very high IQ results. First, most tests don't go that high, so generally the tests cannot give such a high score. Second, ordinary fixed length tests are less reliable in the extremes. The test overall might have a reliability of .90, but it won't have that for people scoring 130+. Here's an example:
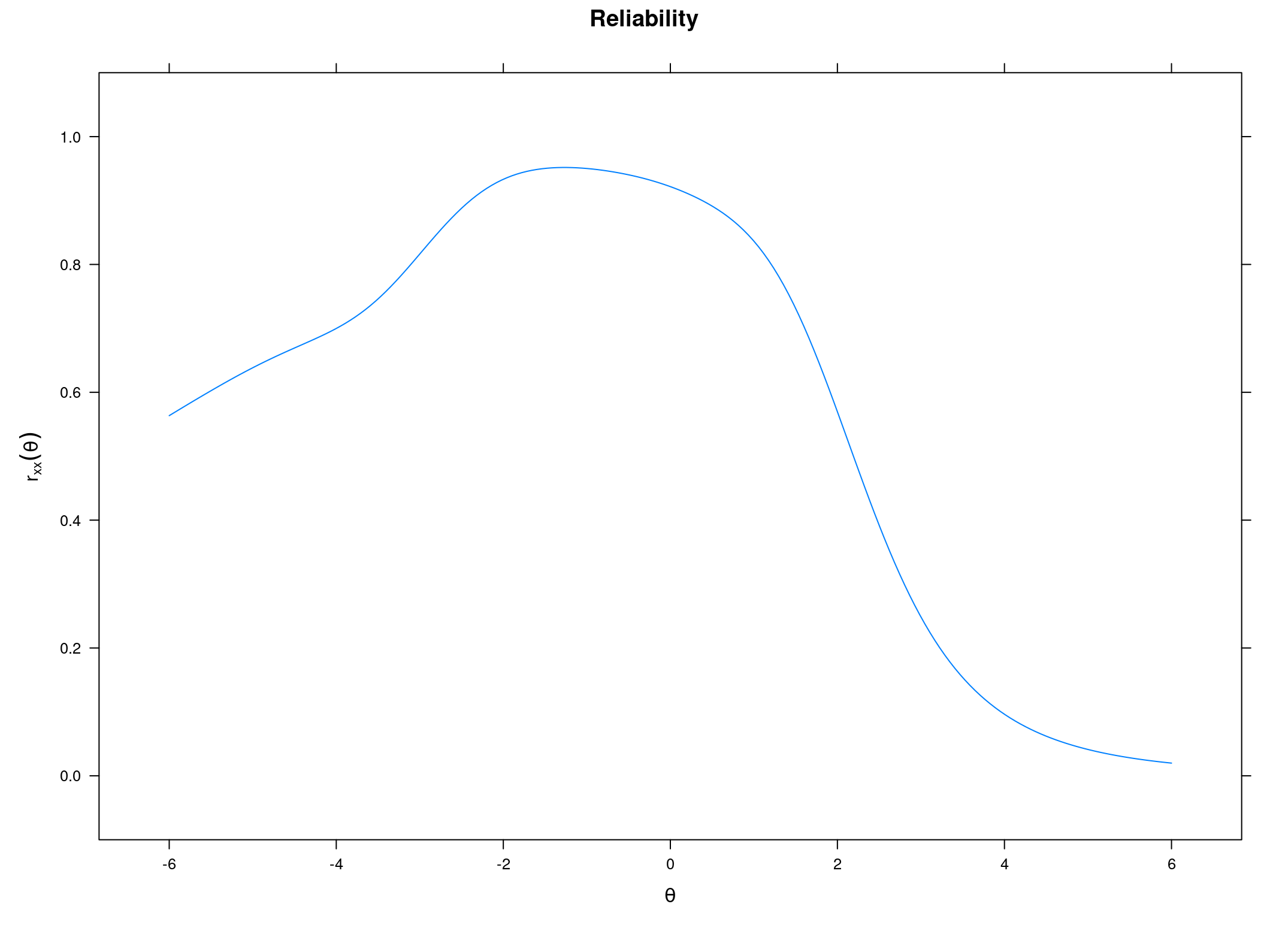
This plot is based on my analysis of the openpsychometrics.org vocabulary test. The test overall has fairly good reliability of .89, but it falls off quickly. Already around the 130 IQ (2 z) level, the test is not very reliable, maybe about .50. Hoel is right that it would be stupid to trust someone's IQ of 140 based on this test.
Still no diminishing returns to intelligence
Next up, Hoel supports the diminishing returns claim. As we have covered this over and over at this blog, it's hardly worth going into again. His particular error was misleading that wage plot with the swapped axes. For more on that one, see my prior post. If you plot the data correctly, looks like this:

Many datasets tend to find a slight increase in validity of IQ at the high end, contrary to Hoel's prediction based on the standard errors. In fact, given the confounding factor of the standard errors increasing, it is surprising that we can nonetheless often see a slight increased validity at the high end. This requires more research using tests that don't suffer from this problem (computer adaptive testing).
What about other studies? Hoel next takes aim at a different study:
So if we actually look at the numbers, there are statistically significant differences in only 48 out of 214 life outcomes in the top 20%, and only 20 out of 214 in the top 10%—and the effects are small too (despite starting from with a very large data set of ~50,000 individuals). Some of the effects are even negative! But this attenuating effect of IQ differentials correlating less and less to outcomes is papered over—instead, victory is declared that there is any detectable difference for IQs above 120 whatsoever.
If we put the increasingly absurd measurement error together with the lack of clear and replicable real-world difference, the simplest explanation when it comes to IQs of, e.g., 150, 160, 170, is that they simply aren’t real. At higher levels, Jack and Jill swap places endlessly, a game of musical chairs as they jump around 30-point spreads with no way to reliably reduce the variance. And what chair they happen to be sitting in for a particular test, ahead or behind, matters not at all to their life outcomes.
His conclusions are bizarre. The study is huge and fails to find much deviation from linearity, more or less the same as every other study on the topic. Larger standard errors at the tails cannot magically change this conclusion, in fact, it would be a bias against this finding, yet we still find it! Here's the abstract of the study:
Despite a long-standing expert consensus about the importance of cognitive ability for life outcomes, contrary views continue to proliferate in scholarly and popular literature. This divergence of beliefs presents an obstacle for evidence-based policymaking and decision-making in a variety of settings. One commonly held idea is that greater cognitive ability does not matter or is actually harmful beyond a certain point (sometimes stated as > 100 or 120 IQ points). We empirically tested these notions using data from four longitudinal, representative cohort studies comprising 48,558 participants in the United States and United Kingdom from 1957 to the present. We found that ability measured in youth has a positive association with most occupational, educational, health, and social outcomes later in life. Most effects were characterized by a moderate to strong linear trend or a practically null effect (mean R2 range = .002–.256). Nearly all nonlinear effects were practically insignificant in magnitude (mean incremental R2 = .001) or were not replicated across cohorts or survey waves. We found no support for any downside to higher ability and no evidence for a threshold beyond which greater scores cease to be beneficial. Thus, greater cognitive ability is generally advantageous—and virtually never detrimental.
The conclusion of the study is exactly opposite of Hoel's claims. Project Talent is an even larger study and it found the same results:

Notice the slightly upwards trend for intelligence and grades. The other regressions are basically linear, as usually found. Again, see my prior post which has many more studies.
Conclusion
Probably the original motivation for Hoel's post is given by this quote:
So if someone regularly talks about IQs significantly above 140 like these were actual measurable and reliable numbers that have a real-world effect, know that they are talking about a fantasy. And if they make claims that various historical figures possessed such numbers, then they’re talking unscientific nonsense. If they’re bragging about themselves, well. . . it’s like someone talking about their astrological sign. Stratospheric IQs are about as real as leprechauns, unicorns, mermaids—they’re fun to tell tales about, but the evidence for them being a repeatedly measurable phenomenon that matters in any meaningful sense of the word is zip, zero, zilch.
Hoel is right about that. People who claim very high IQs are usually narcissistic or mislead. There is no normal way to obtain reliability estimates in that range for normal people. But that's something we can address by designing better tests! It won't be entirely possible to prevent people from cheating and taking the test many times, or secretly training beforehand, but if we really wanted to, we could make a company that tests people in person using modern computer adaptive testing and give people proper high-range results. Is there a market for this? Probably not, but maybe. Certainly, online tests of this kind should be made. In fact, I am coincidentally working on a project like this right now.
So TL;DR Hoel is wrong about most of the specifics, but his general advice to distrust claimed high scores for specific, currently living humans is good.
Thank you for the effort on the piece. I’m happy to debate some points in this, but before that, I just wanted to clear something up first: you definitely attribute things to me here I never said, and attribute to me mistakes I never made. I don’t mean in a vague wishy-washy way where we both kind of have a point in some esoteric statistical argument that's complicated. I mean in a very clear and trackable and simple way, your piece contains mistakes.
To see what I mean, let’s focus on just one part, the one involving Anne Roe. In fact, let’s focus on one sentence. You say “Contrary to Hoel, it is not difficult to figure out the sample sizes of the students or how they were recruited, Roe tells us:”
Then you immediately quote Roe herself, bolding two phrases (I've capitalized them here):
“I made an attempt to get some graduate students to take the same test, just as a matter of general interest, BUT SUCCEEDED IN GETTING ONLY 10, and under circumstances which made it impossible to judge how they had been selected. I then dropped the idea of getting any comparison group until it was announced that tests were to be devised in connection with draft deferment. It then seemed to me that I should make some effort to get a reasonably exact idea of just where these eminent scientists stood in the general distribution of intelligence in the population. Such information might be of use,—particularly in determining the level at which exemption might be considered on this basis,—and was not obtainable anywhere else. I had the great good fortune about then to meet an old acquaintance, Dr. Irving Lorge, who came to my rescue and ARRANGED TO GIVE THE TEST TO ALL STUDENTS MATRICULATING AT TEACHERS COLLEGE, COLUMBIA, FOR A PHD THAT FEBRUARY."
Yet, all the relevant information in that passage is mentioned, very explicitly, in what I wrote on the subject of Roe’s sample, both how they were recruited and their size. Here's the entirety of what I wrote on the matter of Roe's comparison group, so this is the only sentence you could possibly be referring to:
“And while Roe didn’t publish without any comparison group to her chosen geniuses whatsoever, the comparison that she did use was only a graduating class of PhD students (sample size unknown, as far as I can tell) who also took some other more standard IQ tests of the day, and she basically just converted from their scores on the other tests to scores on her make-shift test of SAT questions.”
If you just read that, it makes literally no sense to write that "Contrary to Hoel, it is not difficult to figure out the sample sizes of the students or how they were recruited, Roe tells us:”
In fact, it makes even less sense because you appear to not comprehend what Roe herself wrote, and in the very passage you're quoting! For you also bolded “succeeded in getting only 10" as if that was the information you figured out about sample size. Let’s have that on record. Because this number is wholly irrelevant. It's not the sample size. Go re-read the paragraph. Roe says she attempted to get graduate students, and got only 10, and she couldn’t tell how they were selected. So then she dropped the idea altogether, and didn't use those scores at all (it's just backstory) until she heard about testing and the draft, and redoubled her efforts on her work. Then, later, someone “arranged to give the test to all students matriculating at Teachers College, Columbia, for a PhD that February” and that’s the unknown-sized sample that she used in the book, the one to which she compared the scores on her make-shift test (exactly as I wrote).
So a correct reading comprehension of Roe's passage here should tell us that, unless we can figure out exactly how many students were matriculating at Teachers College, Columbia, for a PhD, in a February of an unknown year sometime around the 1940s or 1950s, then yeah, the sample size of the class is unknown (and even if this number could be tracked down today, or you look at averages of classes, the sample size is not in the uploaded book, so the sentence is true regardless). That's just what she wrote. And what I wrote. Correctly. About what she wrote. But that's not what you wrote.
Overall, happy you took the time, appreciate the effort, but unhappy about the failures of reading comprehension for both me and Roe. That sort of thing would need to get resolved before we move to things like:
(a) Does pulling out the Flynn effect to explain why the past Nobel Prize winners scored so average on questions we find easy today ring convincing, or does it just show off how bad and nonsensical the IQ-to-genius literature is ? (e.g., the Flynn effect is mostly driven from rising averages, not PhD students and intellectuals - go read an older popular novelist and marvel at the vocabulary compared to today!)
(b) Does one graph on IQ and income (the one you show) overrule the other graph (the one I show) and ends the debate, or can I just flash my other graph in return, and so on for eternity?
(c) Is quoting the abstract of a paper I criticized for overstating its case in the abstract, and then reporting essentially the opposite in the results, convincing?
And so on.
Strange to use so much time on Einsteins IQ, a well known fraud.