Tracking ancestry and social inequality using American surnames
Analyzing data for ~11k surnames found in Americans

Our big project was finally published:
Van Pelt, D., & Kirkegaard, E. O. (2026). Big Data, Deep Roots: Correlating Surname Genetic Ancestry and Socioeconomic Status across Millions of Americans. Comparative Sociology, 25(2), 239-280. https://doi.org/10.1163/15691330-bja10162
Genetic variation plays a significant role in shaping socioeconomic status. Conventional census racial categories (Black, White, Asian, Hispanic) obscure substantial variation among ancestry groups. Surnames reflect ancestral lineage and genetic heritage, enabling finer measurement. The authors combined 23andMe genetic ancestry data on surnames with surnames yielded from government financial records, criminal databases, Wikipedia entries, and physician licensure records. They found that genetic ancestry strongly predicted surname-level outcomes across all metrics, with substantial differences in social standing among ethnic groups. Ashkenazi Jews and Indians ranked highest; British/Irish and Iberian ranked lowest among Europeans; highly selected immigrant groups such as Arabs and Iranians scored above Europeans.
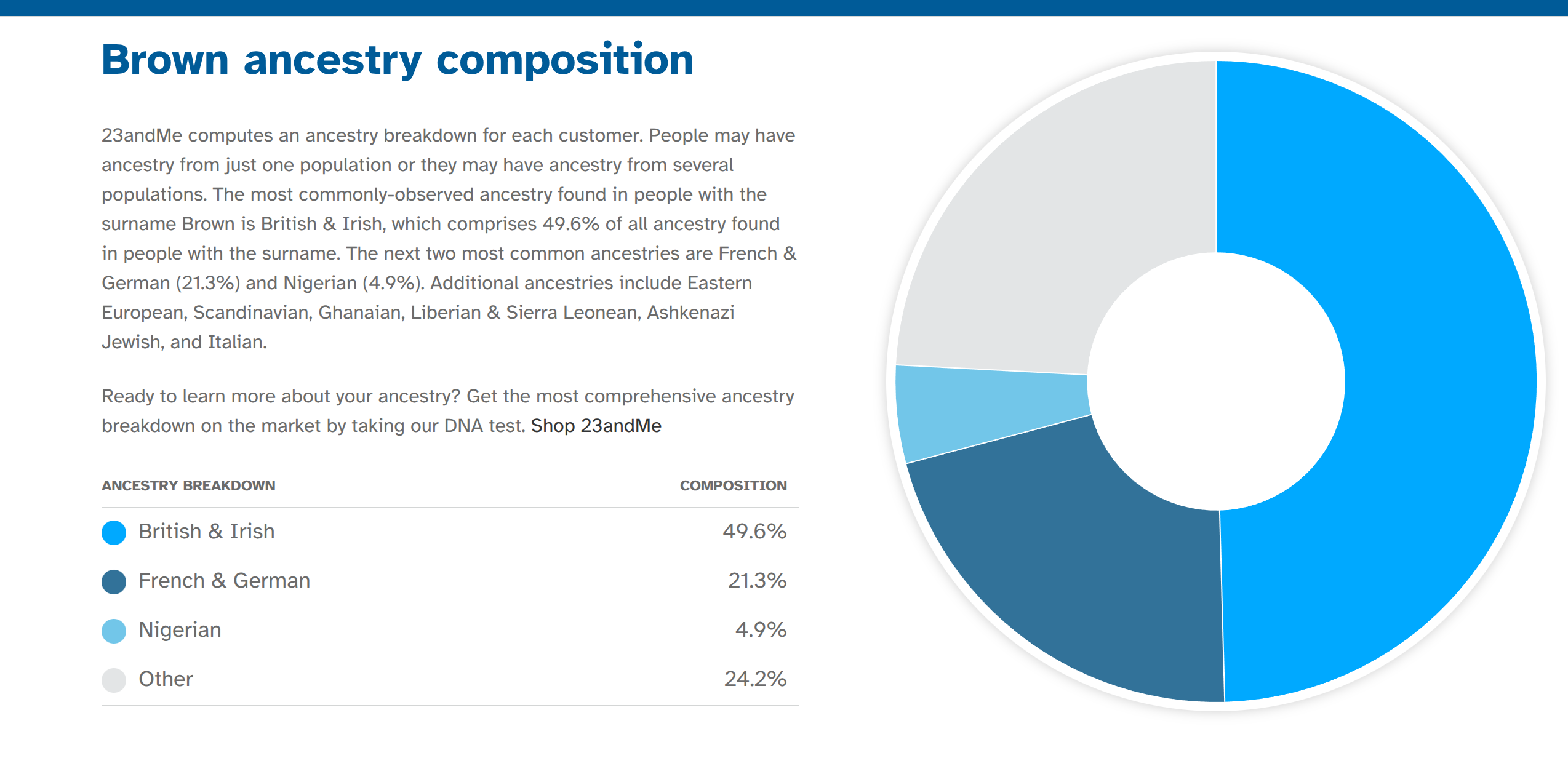
Ancestry-related social gaps are much researched in the USA. Most of the research focuses on the relatively crude racial categories of Black, White, Hispanic, Asian. But there is also some research on the more fine-grained differences. The origin of the study was that some people posted 23andme’s surname page on X. You can look up almost any surname found in the American population there to see statistics about it, including ancestry results from 23andme customers. For instance, looking up “Brown”, we can see that the mean ancestry for this group of customers is: