
Worldwide height variation explained
My new paper with Davide Piffer

There's a lot of variation across the globe in average height. It looks like this (per OWID):

Furthermore, there has been a significant increase in the last century:
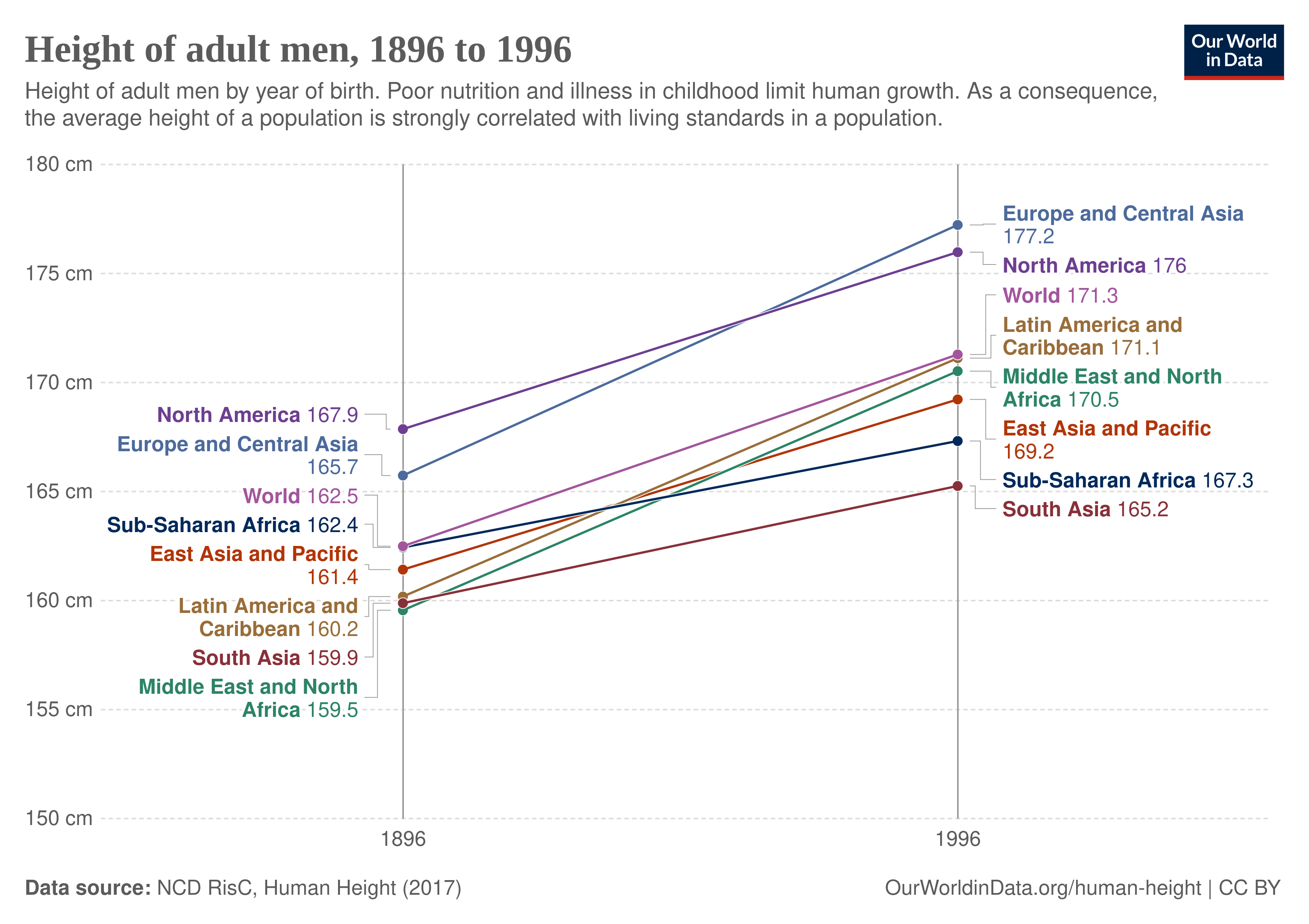
We also know from family research that height variation within a population is almost entirely due to genetic variation, heritabilities are usually above 90% when measurement error is removed. This might lead some to think there's a paradox. If height is 'mostly genetic', how can there be large increases over time? It reflects a misunderstanding of the heritability metric. Heritability metrics provide a static, snapshot-like perspective on causality. It tells you for a given snapshot of society the proportions of causation (e.g. 90% genetic for height variation), but does not tell you anything directly about between cohort differences. Such differences may be caused by genetic or non-genetic causes. A very high heritability within a cohort is compatible with almost no genetic causation of cohort changes. The way this works out mathematically is that the non-genetic factors that change do not vary much between families within a cohort, and thus do not show up in variance analysis. In other words, the causes of height improvement should be causes that affect everybody about equally. Some obvious candidates include sanitation that reduces infectious diseases, antibiotics to clear them further, vaccines to prevent them or diminish their effects, as well as better (more) food. All of these factors have improved massively since the industrial revolution in the 1800s, which then spread across the world.
Economists have historically been very interested in human height because it provides them with an indirect measure of economic growth across time. Along with population density, it has been used to reconstruct GDP/capita values across time and space. However, implicit in this use is that height works as an invariant indicator across time and place. If populations naturally vary in height -- have differences in their average polygenic scores -- then this model fails, and will need some modification. In our new paper, we sought to show that this is the case.
Piffer, D., & Kirkegaard, E. O. (2024). Polygenic Selection and Environmental Influence on Adult Body Height: Genetic and Living Standard Contributions Across Diverse Populations. Twin Research and Human Genetics, 1-18.
We analyzed whole-genome sequencing (WGS) data from 51 populations and combined WGS and array data from 89 populations. Multiple types of polygenic scores (PGS) were employed, derived from multi-ancestry, between-family genome-wide association study (GWAS; MIX-Height), European-ancestry, between-family GWAS (EUR-Height), and European-ancestry siblings GWAS (SIB-Height). Our findings demonstrate that both genetic and environmental factors significantly influence adult body height between populations. Models that included both genetic and environmental predictors best explained population differences in adult body height, with the MIX-Height PGS and environmental factors (Human Development Index [HDI] + per capita caloric intake) achieving an R2 of .83. Our findings shed light on Deaton’s ‘African paradox’, which noted the relatively tall stature of African populations despite poor nutrition and childhood health. Contrary to Deaton’s hypotheses, we demonstrate that both genetic differences and environmental factors significantly influence body height in countries with high infant mortality rates. This suggests that the observed tall stature in African populations can be attributed, in part, to a high genetic predisposition for body height. Furthermore, tests of divergent selection based on the QST (i.e., standardized measure of the genetic differentiation of a quantitative trait among populations) and FST (neutral marker loci) measures exceeded neutral expectations, reaching statistical significance (p < .01) with the MIX-Height PGS but not with the SIB-Height PGS. This result indicates potential selective pressures on body height-related genetic variants across populations.
Davide Piffer did the heavy lifting on this paper as usual, so allow me to provide the pop science write-up. First, famous economist Angus Deaton argued in a 2007 paper that height was problematic because Africans were too tall for their level of development:
Adult height is determined by genetic potential and by net nutrition, the balance between food intake and the demands on it, including the demands of disease, most importantly during early childhood. Historians have made effective use of recorded heights to indicate living standards, in both health and income, for periods where there are few other data. Understanding the determinants of height is also important for understanding health; taller people earn more on average, do better on cognitive tests, and live longer. This paper investigates the environmental determinants of height across 43 developing countries. Unlike in rich countries, where adult height is well predicted by mortality in infancy, there is no consistent relationship across and within countries between adult height on the one hand and childhood mortality or living conditions on the other. In particular, adult African women are taller than is warranted by their low incomes and high childhood mortality, not to mention their mothers' educational level and reported nutrition. High childhood mortality in Africa is associated with taller adults, which suggests that mortality selection dominates scarring, the opposite of what is found in the rest of the world. The relationship between population heights and income is inconsistent and unreliable, as is the relationship between income and health more generally.
Our resolution of this issue is that Deaton was wrong on two points. First, wrong to assume a blank slate model of height differences among populations. As he wrote:
Here I examine international patterns of adult height, focusing on the links among adult height, disease, and national income. Although there is a large genetic component to heights within populations, the contribution of genetics to variation in mean heights across populations is much smaller. Indeed, the large increase in heights in Europe and North America over the last two centuries is clearly not driven by changes in gene pools, even those associated with migration, but by changes in the disease and nutritional environments. So the question arises whether the same is true across populations now, as well as over time within populations whose economic and disease environments are much less favorable than currently prevailing in the rich world.
Deaton's mistake is to assume that across time (cohort) differences are similar to across population or place differences. We might call this Flynn's fallacy as he made the same error when he was pushing the Flynn effect as a rebuttal to racial hereditarianism back in the 1980s. In fact, Deaton offered no evidence in his article that population differences in height did not have a genetic component. In fact, it seems obvious that they do. For instance, we can compare the heights of Asian (mainly Chinese) Americans vs. Chinese at home, or African Americans vs. Africans at home. Consider the plots above, showing that Africans born in 1996 average about 167 cm, but those in USA average about 176 cm (+9 cm). A slight complication here that African Americans have 15-20% European ancestry, but since European Americans are about the same height, this cannot be a big confounding factor. The large differences between same-race people growing up in different countries are plausibly related to environmental differences. Africa is still poor, and China was until recent decades suffering from communism-related poverty. However, within the USA, the Asian vs. European gap remains large, 170 vs. 177 cm, which is about 1 standard deviation (7 cm for men). Clearly, then, it seems the remaining 7 cm gap has largely genetic causes, and that the African vs. European gaps we see across the world relate almost entirely to non-genetic causes.
In our new study, we sought to demonstrate this genetic and environment model across populations. We compiled genetic data from as many populations as we could find, ending up with a maximum of 89 populations (mostly countries). Thus, for these 89 countries, we can calculate average polygenic scores for height and compare these with measures of the environment (e.g. human development index as an overall score) and observed heights (e.g. from above figures).
Important to note here is that egalitarian academics have been claiming that population differences in polygenic scores for various phenotypes (but especially intelligence-related) are due to issues with the model training. First, they claim that because the models are trained on Europeans, they show some bias towards Europeans. How this would work is not entirely clear. How does the statistical model know which direction of effects is the socially desired one? It doesn't, it's just a regression model. This is akin to the norming fallacy for cognitive tests. It used to be popular to claim that because a given test is normed on Europeans (Whites), then it must somehow show bias towards them. Arthur Jensen dealt with this back in 1980 in his book Bias in Mental Testing. However, there is some truth to the matter of training samples affecting results. This has to do with issues related to which genetic variations are measured (arrays only measure certain variants, mainly SNPs), and the ability of statistical models to find the signal for them. Most of the arrays designed for measurement of European DNA focus on variants that are common in Europeans, which thereby excludes some variants that are not common in Europeans but are so in other populations. If by some magic these variants tend to be associated with a direction of effect (e.g. being taller), then their effect will be missed and the resulting polygenic scores will have some bias in estimating the mean. I have written at length about this previously. Hereditarians recognized these issues years before the egalitarians did, so it's not true that they came up with novel criticisms that were devastating to the case. Rather, they were just repeating the same worries hereditarians had mentioned but without giving them credit. Anyway, the solution to this issue is to train the models on a genetically diverse sample, usually called trans-ethnic GWAS. This has become common in the last 5 years or so, and models exist for height as well.
Second, genetic models trained on subjects from different families may have bias. That's because they identify genetic variations that are statistically related to the phenotype (e.g. height), and include those in the score. However, it is possible that some of these associations actually reflect not direct genetic causation (e.g., variant rs123 causes a change in a protein that affects skeletal growth at puberty or affects the expression of some growth hormone), but rather, by coincidence, this variant has become statistically linked to social status which is also linked statistically to height. Genetic variants from between-family genetic models (GWASs) may thus find spurious variants in the sense that they are not causal, or at least, not causal in the sense desired (direct genetic causation). It is possible that such indirect environmental bias in the models will result in polygenic scores that also show this bias (if the direction has some consistency across variants), and this bias may also relate to population differences. Well, maybe. The solution to this is to try to adjust for such confounding. The main method for about a decade has been to include age, sex, and genetic principal components. The latter work as a measure of overall genetic ancestry, though not scaled to 0-100% (e.g., component 1 usually reflects African vs. non-African ancestry). In recent years, it has become recognized that while this control is useful, it may fail to adjust for all of the confounding. The better solution is to use siblings for training the genetic models. Siblings do not differ very much in ancestry, and this difference may not be related to the polygenic scores for a given phenotype. If we imagine 2 siblings of an African American and European American couple, the first sibling may be 42% African and the second may be 40% African (assuming one parent is 80% as is typical). This small remaining 2% point difference cannot bias the model training by a lot, but can still bias a little. The same can be said for other ancestry differences, including relatively minor ones like English British vs. Celtic British, or Anatolian farmer vs. Indo-European (steppe) ancestry. Due to a lack of large datasets of siblings with measured genetic data, sibling models were not used much until the last 5 years or so. In the last years, new genetic models have been released that have been trained on sibling or otherwise family-adjusted data. The most recent paper on this is from Tan et al 2024, so check that out for more details. Importantly, sibling-trained models exist for height now, which can be used to check against this worry.
Thus, being aware of the above problems, we used multiple variants of polygenic scores for height:
MIX-Height. For body height, we used the significant single nucleotide polymorphisms (SNPs) from the largest GWAS to date (Yengo et al., Reference Yengo, Vedantam, Marouli, Sidorenko, Bartell, Sakaue, Graff, Eliasen, Jiang, Raghavan, Miao, Arias, Graham, Mukamel, Spracklen, Yin, Chen, Ferreira, Highland and Hirschhorn2022), which comprised a multi-ancestry sample (after LD pruning with a threshold of r 2 < .1).
EUR-Height. We used the significant SNPs from the European-ancestry subsample of the Okbay et al. (Reference Okbay, Wu, Wang, Jayashankar, Bennett, Nehzati, Sidorenko, Kweon, Goldman, Gjorgjieva, Jiang, Hicks, Tian, Hinds, Ahlskog, Magnusson, Oskarsson, Hayward, Campbell, Porteous and Young2022) GWAS.
SIB-Height. Summary statistics for sibship (within-family) GWAS of body height were retrieved from the largest meta-analysis of sibship GWAS (Howe et al., Reference Howe, Nivard, Morris, Hansen, Rasheed, Cho, Chittoor, Ahlskog, Lind, Palviainen, van der Zee, Cheesman, Mangino, Wang, Li, Klaric, Ratliff, Bielak, Nygaard, Giannelis and Davies2022). There were 290 SNPs that remained significant after clumping and applying a significance threshold (p < 5 × 10-8, LD r 2 < .1). Within-family GWASs, specifically sibship studies, offer unique advantages in genetic research. By comparing siblings who share approximately 50% of their genetic material and a common family environment, these studies can better isolate the effects of specific genetic variants on body height. This approach helps control for confounding factors such as population stratification and shared environmental influences that can bias traditional GWAS results. However, sibship studies also have limitations, including smaller sample sizes and reduced statistical power due to the lower phenotypic and genotypic variance within families compared to between families. Despite these practical constraints, sibship GWAS provide valuable insights into the genetic architecture of complex traits like body height (Howe et al, Reference Howe, Nivard, Morris, Hansen, Rasheed, Cho, Chittoor, Ahlskog, Lind, Palviainen, van der Zee, Cheesman, Mangino, Wang, Li, Klaric, Ratliff, Bielak, Nygaard, Giannelis and Davies2022).
Unfortunately, the issues with the Howe et al 2022 sibling study noted by Tan et al 2024 study did not come out in time for our paper. We will use the newest scores in the next iteration of our work.
Using the full sample of populations (89), the correlation matrix looks like this:

The first 4 columns are of primary interest. The first 3 columns are the 3 versions of the polygenic scores for height, and the 4th is observed heights. So actual heights correlate between 0.58 and 0.26 with the height polygenic scores. Only the sibling score is not beyond chance (p > 0.05). This could be taken as evidence that the other correlations are spurious, or at least, partially spurious. However, given the limited sample size of 89, the difference is not that reliable. Note that the different polygenic scores correlate between 0.57 and 0.91. The important test is not whether polygenic scores for height predict height by themselves, but whether they predict them in combination with environmental factors. Thus, let us look at the regression models:
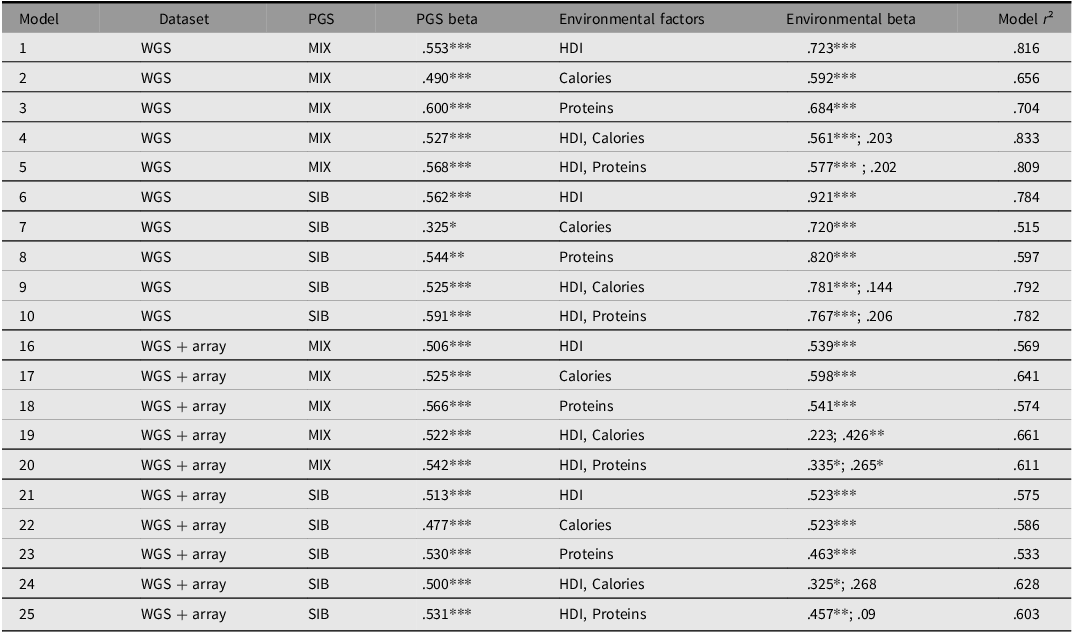
The first 10 rows concern the reduced dataset using only whole genome sequencing data. This gives better coverage of the included variants in the models, but a smaller sample of populations. The last 10 rows concern the full dataset (some models are left out, hence the skip from 10 to 16). We see that the sibling polygenic scores combined with any measure of the environment produces strong statistical models, with both genetic and environmental predictors being important (p < .001). Since it was not clear a priori which measure of the environment was best, we tried different ones, which is why there are 5 models per polygenic score version (models 21-25 used the sibling polygenic scores). In the last two models, two measures of the environment were included to see which one seemed most important. It shows that HDI seems the most important. Still, no matter which combination of genetic scores and environmental variable were used, the predictive validity of the genetic scores was about 0.50, and overall the model explained 50-60% of the variance in global height. This is not perfect, but it is a good start.
The next worry was that despite the use of sibling genetic models, there was still some kind of bias left. Additionally, it is possible that unobserved environmental variables could account for the apparent validity of the genetic scores. The normal way to deal with this is to use a phylogenetic model. In this approach, a specific tree of relatedness is assumed and populations have a place on them. This is commonly used in cross-species comparisons in animal ecology. For humans, however, it is difficult to use because human genetic variation does not follow a strict tree-like structure. Some groups have mixed since diverging, and thus there is horizontal genetic transfer, not only vertical. Furthermore, we didn't have any phylogenetic tree of all of our 89 populations. Thus, we settled on another approach using autocorrelation models. In many kinds of datasets, some observations have relationships to others. Most obviously, in time-series data, one can predict the value by looking at the prior value for the same unit, termed autocorrelation (self-correlation). However, the concept can be expanded to units that follow any kind of dimensional structure, such as neighboring units on a map, e.g. districts within a city, regions within a country, or countries on the world map. In the same way, one can calculate the genetic distances using Fst values between all the populations. This can then be used to predict the value of a given population using only the values of its neighbors, a kind of genetic nearest neighbor regression. What this does is test whether the polygenic scores can predict height differences beyond what one can predict knowing the heights of the nearby populations. This is thus a way to test for signal in the scores beyond just indicating a broader ancestry group. The models otherwise work the same as before, and we include an environmental variable along with the polygenic scores.

There are two spatial models. In the autoregressive model, there is a lag term, the prediction from genetic neighbors (defined by Fst distance below a threshold). This is in addition to the polygenic score and HDI as the overall environmental variable. In the spatial error model, there is a two-step approach where the residuals from the first model are assumed to be caused by the lag variable as well as a random error. The models make different causal assumptions, so we wanted to see if they would produce consistent results. We find that every model finds signal of the polygenic scores, p < 0.01, though with somewhat reduced effect sizes (betas about 0.40 down from 0.50). Likewise, HDI continues to predict height independently of the polygenic scores, and the expectation from the genetic neighbors.
Finally, we used a standard test for divergent selection based on the Qst/Fst pair. This test has lower power, we think, than the use of polygenic scores. Essentially, it tests whether there is more variation in the polygenic scores than one would expect by chance variation.
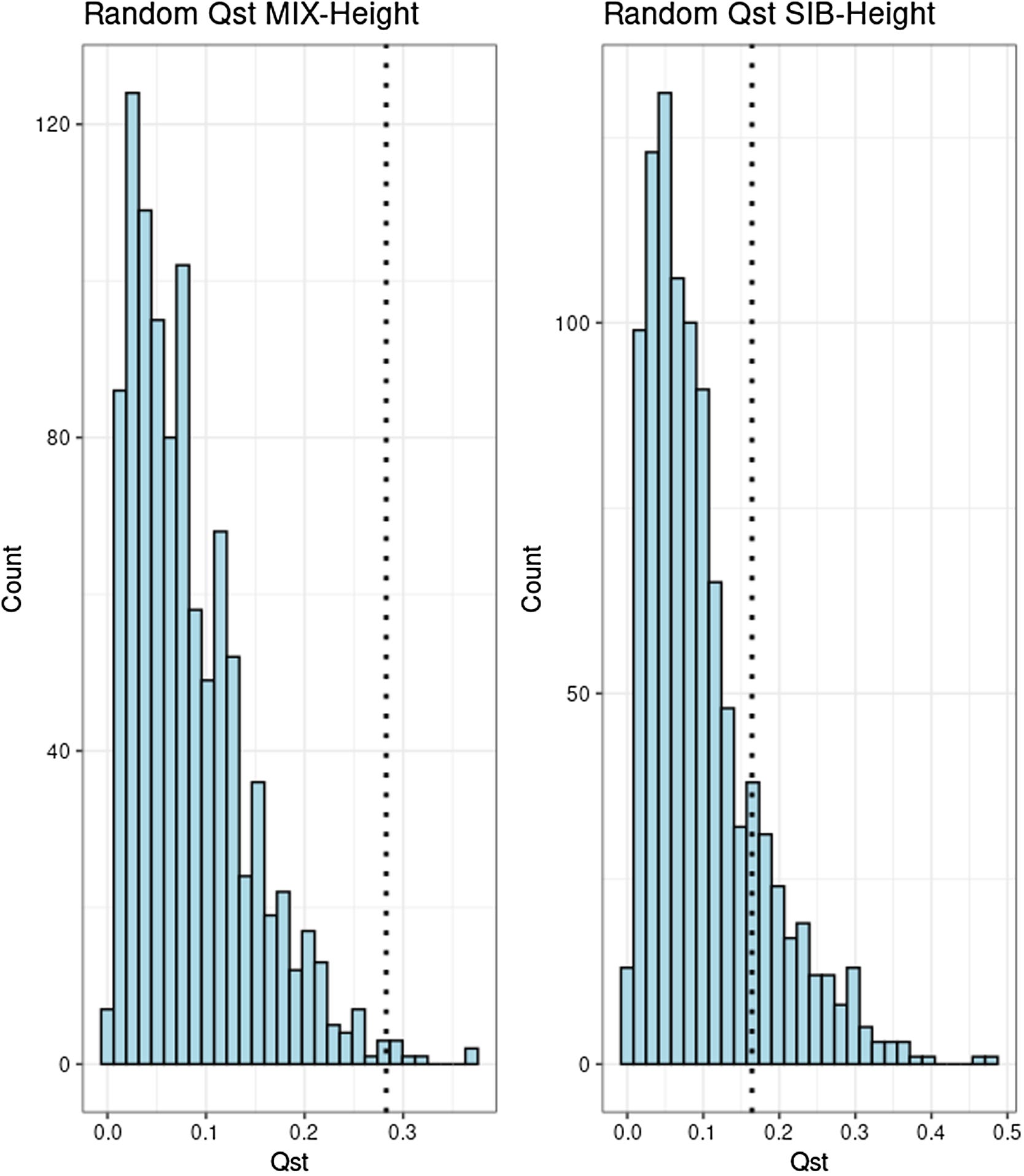
For the high powered genetic model (mixed ancestry, between families), the test found evidence of divergent selection (p < 0.01). The sibling model did not find much evidence. We interpret this as being due to lower power, as the sibling genetic model (GWAS) only had about 100 SNPs. Time will tell whether future, larger GWASs will start showing results. Maybe with the new and improved sibling models from the Tan et al 2024 paper, but those weren't ready at the time we did this work.
Discussion
Overall, I'm very happy with our study. We showed that contrary to common claims, one can use polygenic scores across populations to investigate differences in something like height. It didn't matter so much for most of the analyses whether one used European-derived, mixed ancestry-derived, or sibling-derived scores. Furthermore, clearly environmental factors are important in explaining worldwide height variation. It should be said that, given the general hereditarian model, what we treated as a non-genetic variable here, HDI, is partially an effect of other genetic differences, chiefly in intelligence. As such, the polygenic score for intelligence indirectly causes heights to go up through its effects on nutrition, sanitation, and general nation building. We look forward to seeing what the egalitarians will say to our work. So far, they have been awfully quiet.
Hey could you respond to this it's some Google doc trying to debunk IQ https://t.co/vpK0FPm4yu
I think you might find this study interesting:
https://www.cell.com/current-biology/fulltext/S0960-9822%2822%2900108-7
Steppe ancestry within Estonians predicts height. If to this day proportion of ancestry from an ancient population can predict height within an ethnic group, I think it’s fair to say that ancestry can predict height differences to some extent between modern groups. Other papers have suggested the height difference between Northern and Southern Europeans can be explained entirely by ancestry differences